2021 年,我国《数据安全法》和《个人信息保护法》正式落地执行,明确了行业数据、个人信息的分类分级保护原则;同时要求数据在生命周期各环节中,应要有相应的安全防护。医疗行业作为重要的关键基础设施行业,国家对医疗行业的安全建设提出了更高的要求,相继出台了各类法律法规,并要求各省市和医疗机构做好数据分类分级工作,保障数据安全。如《信息安全技术健康医疗信息安全指南》、《电子病历系统功能应用水平分级》、《全国医院信息化建设标准与规范》、《医院信息互联互通标准化成熟度测评》等。
某医院作为某省规模最大的三级甲等综合性医院,存储大量病人信息、医护人员信息、疾病信息、生产运营数据。数据一旦遭到泄露和破坏,会严重影响医院诊疗以及其他业务正常开展,因此医院需要对院内数据的分布、敏感级别、开放共享条件等进行有效感知,不断提高敏感数据的识别能力。
随着我国对医疗机构个人医疗数据安全的重视程度和监管力度逐渐增强,为确保医院个人医疗数据分类分级工作和数据安全管理流程符合行业主管部门和监管部门的要求,希望通过本文对国家、行业、区域的相关标准和规范提供一定的参考,并帮助实现医院数据分类分级落地。本文是面向医院电子病历数据分级范围,以及电子病历数据定级的要素、规则和定级过程的建议和安全实施参考。
1. 定级目标和范围
对医院数据资产进行全面梳理,并针对诊疗过程中产生的患者电子病历数据进行适当的定级,是医院实施数据分级管理的基础,是实现医院数据安全和开发利用平衡的有效途径。医院数据的分级管理是建立统一的数据安全框架的基础工作,目标是为制定有针对性的数据安全措施提供支撑。
医院数据定级工作所涉及的数据主要包括:进行诊疗服务过程中直接或间接采集、产生的电子病历数据,包括诊疗信息、影像检查信息、检验信息、健康查体信息等。
2. 医院数据分类
医院数据的分类,一方面可以围绕电子病历数据进行分类,从而能够适合医院业务场景和过程,便于数据分类管理。另一方面,医院电子病历数据是围绕患者就医过程进行采集和产生的,因此将个人信息标识数据作为分类的一部分,能够更加适合个人信息保护的要求。
2.1 个人信息
根据 HIPPA《健康保险可携性和责任法案》、和我国颁布的《个人信息保护法》、《(GB/T 35273-2020)信息安全技术—个人信息安全规范》的要求,都提出了保护个人信息的要求,特别是保护个人可识别信息。因此对于“个人可识别信息”的确定,需要作为一个专门的分类:
1、个人信息标识性的数据(个人标识数据)
| 个人标识数据 | 说明 |
| 姓名 | 个人的完整姓名 |
| 地址 | 所有小于县市的地理细分,例如区、镇、街道地址 |
| 日期 | 所有与个人直接相关的日期元素( 除年份外),包括出生日期、入院日期、出院日期、死亡日期 |
| 电话号码 | |
| 手机号码 |
| 个人标识数据 | 说明 |
| 传真号码 | |
| 电子邮件地址 | |
| 身份证号码 | |
| 居民健康卡号码 | 患者持有的全国统一的居民健康卡的编号 |
| 健康档案编号 | 城乡居民个人健康档案的编号 |
| 账户号码 | 微信号、支付宝号码等支付账户信息 |
| 车辆标识符、序列号或车牌号 | |
| 设备标识符和序列号 | |
| 生物标识符 | 基因、指纹、声纹、掌纹、耳廓、虹膜、面部特征 |
| 个人图像 | 全脸摄影图像和任何类似的图像 |
| 遗传信息 | 可识别个人的遗传信息 |
2、个人属性或统计性信息(弱标识)
指的是无法唯一标识个人信息,只能标识一定“范围”的患者个人。包括:年龄、性别、血型、籍贯、学历、职业、民族、国籍、婚姻状况、工作单位。
2.2 电子病历诊疗数据
电子病历数据是体现患者就医过程的完整数据,电子病历数据的分类可以结合诊疗过程收集、 产生、处理的数据进行分类,包括挂号、处方、用药、健康状况(病史、过敏史等)、医嘱信息、 检查检验信息、手术麻醉信息、助产信息、护理信息、出入院记录信息等,覆盖完整的电子病历数据。
3. 医院数据分级
电子病历数据的定级,应该从患者个人隐私数据泄露和患者诊疗隐私数据泄露的维度,并遵循平衡数据安全和开发利用的目标,对数据字段和数据集进行敏感级别定义。
3.1 分级思路
对于个人隐私保护和数据利用平衡的关键点,就在于能否切断隐私数据与个人标识数据之间的联系:越是对外, 越是公开场合,对于将个人信息和诊疗隐私数据的联系的切割要求越强烈,也就是去标识化的要求越强烈。
医院电子病历数据分级的主要思路如下:
1、医院在业务开展过程中存在较多的个人基础数据,这些数据属于个人隐私,需要保护。
2、患者在诊疗过程中,存储记录有患者的病症、病情、检查、临床数据等个人诊疗隐私数据需要保护。
3、无论是个人基础数据还是患者诊疗数据,都有对个人进行强标识的标识数据。
综上,电子病历数据分类分级的关键就是合理地对个人属性(字段)信息规定出对应的标识级别,以及诊疗隐私数据属性(字段)信息的级别;同时定义出这些不同级别的个人标识数据和诊疗隐私数据组合产生的数据集(表和数据组合)的敏感级别;最后可以根据不同的应用场景,定义出所能访问的敏感数据集级别,以及该场景所适合的去标识化或脱敏的要求。
例如:导出下载临床数据,用于疾病研究,需要对患者的个人标识数据进行去标识化处理。
3.2 个人信息字段分级
针对电子病历数据中的个人信息的分级,建议根据个人信息的标识程度进行分级。例如:
1)身份证号、手机号能够唯一的关联到患者个人,其对个人信息的标识程度属于“强标识”。
2)在诊疗过程中采集的生物标识、设备号、姓名等个人信息,无法直接关联,但很容易通过其他数据关联到具体的个人身份。
3)患者的出生日期等信息能够关联到一定“范围”的个人,属于“弱标识”信息。
4) 患者的年龄、血型、学历等信息属于患者的“特征”性质的数据,与具体个人的关联更加弱。
综上,我们对电子病历数据中的对和个人信息相关的表字段的具体分级建议如下:
- A4 数据:个人身份标识性信息,属于个人信息的强标识数据,能够唯一关联到个人,包含证件号码、电话号码、健康卡号、城乡居民健康档案编号、地址 ( 详细到门牌号 )、电子邮件地址等。
- A3 数据:个人间接标识性信息,属于个人信息的标识数据,能够间接关联到个人,包括姓名、生物标识(如基因)、(个人手机 / 设备)设备标识符和序列号、IP 地址(个人设备地址)、全脸摄影图像和任何类似的图像等。
- A2 数据:个人弱标识性信息,能够确定较小范围的个人弱标识数据,包括出生日期、所属行政区域、邮政编码、单位电话号码、单位名称等。
- A1 数据:个人特征性、统计性信息,包括年龄、血型、性别、学历、籍贯等,以及相应的代码。
3.3 电子病历诊疗数据字段分级
针对电子病历数据中的诊疗数据的分级,建议根据患者数据隐私程度进行分级。例如:
1) 门诊号、住院号等可以检索到患者的整个诊疗记录的数据,能够唯一关联到患者的诊疗记录。
2) 患者的病症、用药、医嘱、检验数据等反映患者的病情和身体特征的隐私数据、临床数据, 这些数据体现了患者的隐私。
3) 麻醉、测量、护理、耗材、交费金额等数据,是患者在诊疗过程中产生的过程数据,这些数据不体现患者诊疗隐私信息。
4)设备信息、药品信息等数据,属于诊疗无关的医院基础资源和管理信息,与个人隐私无关。
综上,我们对电子病历中除个人信息以外的患者诊疗数据字段的具体分级建议如下:
- C4 数据:门诊号、处方号、住院号等可以检索到患者的整个诊疗记录的强标识数据。
- C3 数据:病症、用药、医嘱、检验等反映患者的病情和身体特征的隐私数据、临床数据的字段。
- C2 数据:麻醉、测量、护理、耗材等诊疗的过程产生的数据,不体现患者诊疗隐私信息的字段。
- C1 数据:医院的设备、药品等诊疗无关的医院基础资源和管理信息数据字段。
3.4 数据集合分级
前面我们对电子病历中的个人信息和诊疗数据的字段进行了分级,更关键的,所有对数据的存储和数据的访问都将以数据集合的形式存在,单一字段的数据通常不会泄露患者的隐私数据。因此, 对数据集合的定级更为关键。
因此,建议从患者个人隐私数据泄露和患者诊疗隐私数据泄露的维度,对数据集也就是数据表、数据访问集合进行敏感级别定义。
- L4 级数据属于高敏感数据,会直接地泄露患者的个人隐私数据(A3 及以上数据)和个人诊疗敏感数据(C3 数据);例如:电话号码 + 姓名、电话号码 + 现病史等。
- L3 级数据属于敏感数据,会对个人隐私数据(A3 及以上)和个人诊疗敏感数据(C3 数据)提供较为直接的引导;例如:IP+ 生物标识、姓名 + 门诊号等。
- L2 级数据属于弱敏感数据,直接或间接地泄露患者的就诊过程数据(C2 数据)或者个人一般数据 (A2 及以下 );会引起对患者某方面病症的猜测;或者会对发现个人高度隐私数据(A3 及以上)和个人诊疗敏感数据(C3 数据)提供较为间接的引导;例如:姓名 + 出生日期、姓名 + 护理记录。
- L1 级数据是非敏感数据,不会泄露个人隐私和患者隐私;例如:出生日期+ 性别、年龄+ 病症。
根据上述的数据集合分级原则,数据集合的具体分级建议如下:
表:电子病历数据集合分级建议
| 数据集合类型 | 数据集合 | 数据集合示例 | 数据级别 |
| 患者个人信息数据集 | A4+A4 | 身份证号 + 电话号码 | L4 |
| A4+A3 | 电话号码 + 姓名 | L4 | |
| A3+A3 | 姓名 + 虹膜 | L3 | |
| A4+A2 | 身份证号 + 出生日期 | L3 | |
| A4+A1 | 身份证号 + 年龄 | L3 | |
| A3+A2 | 姓名 + 出生日期 | L2 | |
| A3+A1 | 姓名 + 年龄 | L2 | |
| 其他 | 出生日期 + 学历 | L1 | |
| 无个人信息的医疗数据集合 | C4+C3 | 门诊号 + 医嘱 | L3 |
| C4+C2 | 门诊号 + 护理记录 | L2 | |
| 其他 | 医嘱 + 体检结果 | L1 | |
| 个人信息与医疗数据集合 | A4+C3 | 电话号码 + 医嘱 | L4 |
| A4+C4 | 电话号码 + 门诊号 | L3 | |
| A3+C4 | 姓名 + 门诊号 | L3 | |
| A3+C3 | 姓名 + 医嘱 | L3 | |
| A4+C2 | 电话号码 + 护理记录 | L2 | |
| A3+C2 | 姓名 + 护理记录 | L2 | |
| A3+C1 | 姓名 + 设备信息 | L2 | |
| A2+C4 | 出生日期 + 门诊号 | L2 | |
| A2+C3 | 出生日期 + 医嘱 | L2 | |
| 其他 | 出生日期 + 护理记录 | L1 |
3.5 医院数据脱敏降级处理建议
为了实现在保护个人信息和患者隐私的同时,让医疗数据可以得到充分的利用,可以通过对敏感数据脱敏、匿名化处理,实现个人标识数据和诊疗数据降级,降级后的数据,不再具备标识性和敏感性。
个人信息降级处理,是通过将 A4、A3 级别的个人信息进行脱敏或匿名化处理,经过处理后的个人信息无法再标识到患者个人。具体建议如下:
1、身份证号脱敏
格式:十八位数字,六位数字地址码,八位数字出生日期码,三位数字顺序码和一位数字校验码。
脱敏前级别:A4
| 脱敏方法 | 规则 | 示例 | 脱敏后级别 | 建议场景 |
| 仿真替换 | 替换日期内容 | 替换前:120102198303201630 替换后:120102199105161630 |
A2 | 开发测试统计分析 |
| 替换地址内容 | 替换前:120102198303201630 替换后:110106198303201630 |
A2 | 开发测试统计分析 | |
| 替换顺序码和校验码 | 替换前 :120102198303201630 替换后:120102198303202331 |
A2 | 开发测试统计分析 | |
| 掩码遮蔽 | 遮蔽日期和顺序码 | 遮蔽前:120102198303201630 遮蔽后:1201021983*******0 |
A1 | 数据展示运维保障数据导出病例分析、研究 |
2、手机号脱敏
格式:11 位数字,号段 3 位 + 归属地编号 4 位 + 流水号 4 位。
脱敏前级别:A4
| 脱敏方法 | 规则 | 示例 | 脱敏后级别 | 建议场景 |
| 替换 | 替换归属地编号内容 | 替换前:13820347832 替换后:13874317832 |
A2 | 开发测试统计分析 |
| 替换流水号内容 | 替换前 :13820347832 替换后:13820343326 |
A2 | 开发测试统计分析 | |
| 掩码遮蔽 | 遮蔽归属地编号 | 遮蔽前:13820347832 遮蔽后:138****7832 |
A1 | 数据展示运维保障数据导出病例分析、研究 |
| 遮蔽流水号 | 遮蔽前:13820347832 遮蔽后:1382034**** |
A1 | 数据展示运维保障数据导出病例分析、研究 |
3、地址脱敏
格式:包含省、市、区县、街道和门牌号的详细地址
脱敏前级别:A4
| 脱敏方法 | 规则 | 示例 | 脱敏后级别 | 建议场景 |
| 仿真替换 | 替换门牌号 | 替换前: 北京市海淀区花园路 1 号 替换后: 北京市海淀区花园路 22 号 |
A3 | 开发测试统计分析 |
| 替换街道和门牌号 | 替换前: 北京市海淀区花园路 1 号 替换后: 北京市海淀区紫竹院 22 号 |
A2 | 开发测试统计分析 | |
| 替换区县和街道门牌号 | 替换前: 北京市海淀区花园路 1 号 替换后: 北京市朝阳区呼家楼 17 号 |
A2 | 开发测试统计分析 |
| 脱敏方法 | 规则 | 示例 | 脱敏后级别 | 建议场景 |
| 截断 | 截断到街道 | 截断前: 北京市海淀区花园路 1 号 截断后: 北京市海淀区花园路 |
A3 | 数据展示运维保障数据导出病例分析、研究 |
| 截断到区县 | 截断前: 北京市海淀区花园路 1 号 截断后: 北京市海淀区 |
A1 | 数据展示运维保障数据导出病例分析、研究 | |
| 掩码遮蔽 | 遮蔽到区县 | 遮蔽前: 北京市海淀区花园路 1 号 遮蔽后: 北京市海淀区 ********* |
A1 | 数据展示运维保障数据导出病例分析、研究 |
4、电子邮件地址脱敏
格式:邮箱名 @ 邮件服务器地址
脱敏前级别:A4
| 脱敏方法 | 规则 | 示例 | 脱敏后级别 | 建议场景 |
| 仿真替换 | 替换邮箱名 | 替换前: zhangsan@abc.com 替换后: lisi@abc.com | A2 | 开发测试统计分析 |
| 替换邮件服务器 | 替换前: zhangsan@abc.com 替换后: zhangsan@123.com | A3 | 开发测试统计分析 | |
| 掩码遮蔽 | 遮蔽邮箱名 | 替换前: zhangsan@abc.com 替换后: zh*******@abc.com | A1 | 数据展示运维保障数据导出病例分析、研究 |
5、姓名脱敏
格式:若干汉字
脱敏前级别:A3
| 脱敏方法 | 规则 | 示例 | 脱敏后级别 | 建议场景 |
| 仿真替换 | 替换名 | 替换前: 张三丰 替换后: 张二嘎 |
A2 | 开发测试统计分析 |
| 替换完整姓名 | 替换前: 张三丰 替换后: 郭靖 |
A2 | 开发测试统计分析 | |
| 掩码遮蔽 | 遮蔽名字 | 遮蔽前: 张三丰 遮蔽后: 张 ** 或 张某某 |
A1 | 数据展示运维保障数据导出病例分析、研究 |
6、诊疗标识号脱敏
诊疗标识号包含了患者诊疗过程中的过程中的门诊号、住院号等可以检索到患者的诊疗记录的各种唯一性标识号。
格式:若干位的字符 + 数字编码,一般包含了日期和顺序号,不同机构的定义不同。
脱敏前级别:C4
| 脱敏方法 | 规则 | 示例 | 脱敏后级别 | 建议场景 |
| 仿真替换 | 替换日期内容 | 替换前: 20230112019625412821 替换后: 20220321019625412821 |
C2 | 开发测试统计分析 |
| 替换顺序号内容 | 替换前: 20230112019625412821 替换后: 20230112019627367634 |
C2 | 开发测试统计分析 | |
| 掩码遮蔽 | 遮蔽顺序号内容 | 遮蔽前: 20230112019625412821 遮蔽后: 2023011201962******* |
C1 | 数据展示运维保障数据导出病例分析、研究 |
综上,数据脱敏和匿名化处理能够有效降低数据的敏感度级别,消除诊疗数据和个人的关联。但是,随着数据量的增加和数据的多样化、复杂化,可能会出现脱敏处理后的数据存在“重标识”的风险,对于在脱敏数据规模大、数据内容复杂多样的情况下,要进行脱敏后数据重标识风险的评估。
同时要重点关注数据的多方聚合的场景,多种单一业务用途的数据经过集中、清洗、转换、重组、关联分析等处理之后,相对于原始聚合前的数据,其安全级别可能会发生上升,例如数据融合、多学科会诊聚合多种患者数据等数据聚合场景。因此,建议对此种聚合场景的数据的安全级别要进行更为严格的定级评估。
4.. 医院数据分类分级实施参考
数据分类分级能力是指根据数据的属性或特征,将其按一定的原则和方法进行区分和归类,并且能够根据数据内容敏感程度与危害性对数据进行定级,为数据全生命周期管理的安全策略制定提供支撑。
医院通过建立数据分类分级体系,梳理数据资产,确定数据重要性和敏感度实现对数据实现全方位的管控,并根据不同等级不同类别的数据进行利用和保护,在保证数据安全的基础上促进数据开发利用。
4.1 数据分类分级目标
1、构建统一的数据分类分级标准体系和管理机制
2、确立行之有效的数据分类分级建设方法
3、厘清数据资产,服务医院数据战略和数据治理
4.2 数据分类分级原则
数据分类分级需要满足科学性、稳定性、实用性及扩展性等原则,确保分类分级工作的有效开展和后续落地应用。
表:数据分类分级依据原则表
| 依据原则 | 简要描述 | |
| 数据分类 | 1、系统性 | 数据分类体系应是层层划分、层层隶属、从总到分的,且有单一明确的划分依据。 |
| 2、规范性 | 分类名称应能确切表达数据类目的实际内容范围,其内涵、外延清楚,语义一致。 | |
| 3、稳定性 | 数据分类应以分类对象的最稳定的本质特性为基础和依据,明确数据属性。 | |
| 4、明确性 | 同一层级的数据类目间应界限分明,非此即彼。 | |
| 5、扩展性 | 数据类目设置或层级划分应保留适当余地,方便后续分类数据增加。 | |
| 数据分级 | 1、依从性 | 数据等级划分应满足相关法律、法规及监管要求。 |
| 2、可操性 | 避免对数据进行过于复杂的分级规划,保证数据分级使用和执行的可行性。 | |
| 3、时效性 | 数据的分级具有一定的有效期。 | |
| 4、自主性 | 可根据自身数据管理需要,按照数据分级方法自主确定更多的数据层级。 | |
| 4、合理性 | 数据级别应具有合理性,不能将所有数据集中划分一两个等级中。 | |
| 5、客观性 | 数据的分级规则是客观并可以被校验和检查的。 |
4.3 数据分类分级策略
数据分类分级主要有精细化分类分级与简单化分类分级两种模式(见下表)。精细化分类分级以系统的数据字典为基础,对所有元数据进行分类分级,给出对应的管理对策。简单化分类分级则是根据常见场景,在一个或两个分类的维度下将数据划分为界限清晰的若干等级,一般是以业务和岗位角色进行分类,以数据应用范围进行分级。
表:数据分类分级模式表
| 精细化分类分级 | 简单化分类分级 | |
| 优点 | 覆盖面广,可以防止盲点; 可以实现精细化管理; 适应性强,能适应各种业务应用场景; |
人力物力投入比较少; 见效比较快; 易于维护,实用性强; |
| 缺点 | 敏感数据识别困难,结构复杂,人力物力投入比较大; 见效需要有一个过程; 难于维护,实用性不强; |
覆盖面较窄,可能会产生盲点; 不能满足特殊或小概率业务的需求; |
4.4 建设路径
数据分类分级工作开展首先需要明确工作的实施流程,包括建立组织保障、梳理数据资源、确定数据分类分级策略、数据分类、数据分级、落地及长期运营,具体如下所示:
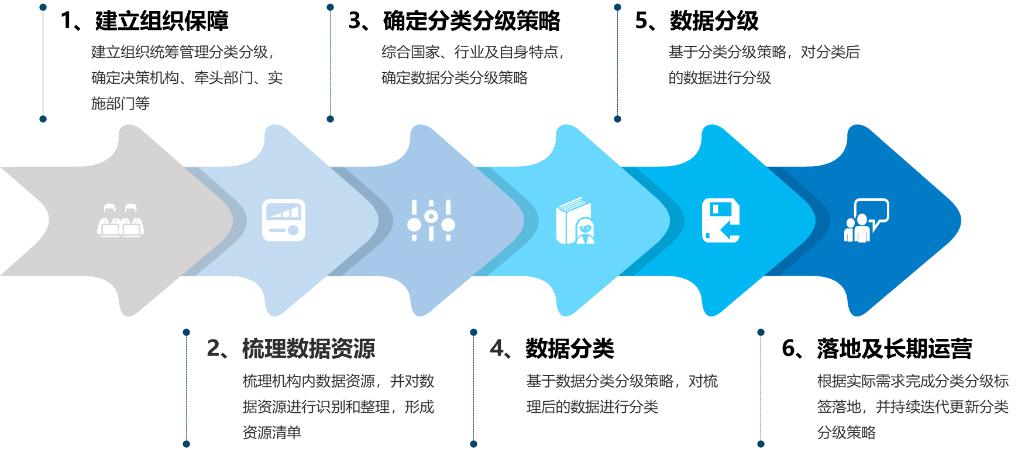
图 1 数据分类分级工作流程图
4.5 具体建设方法
数据分类分级应该严格按照建设路径执行,几个关键节点如下:
1、需求调研:对医院数据战略规划、数据建设情况、业务需求、信息安全环境进行深入调研,分析医院数据管理现状,以得出数据资产状况,指导数据分类分级工作。
2、建立数据分类分级组织保障:在工作启动之前,医院内部建立数据分类分级组织体系,成立数据分类分级工作组,确定该项工作的决策组织、实施部门支撑部门等,整体保障数据分类分级工作的有序开展。
3、梳理数据资源:主要针对医院内部以电子形式记录的数据表、数据项、数据文件等数据内容,整理和识别数据信息,并对数据进行合并统一,形成数据资源列表。
4、制定数据分类分级策略:基于梳理完成的数据资源,全面梳理组织或机构的业务,按照业务属性和数据重要程度等多方面因素进行细分,得出数据分类分级结果。
数据分类分级流程如下:

图 2 数据分类分级流程图
数据分类是基于已经梳理和识别完成的数据资源和业务条线梳理成果,然后按照数据性质(特定的数据性质有所区别)、重要程度(与其他数据相比重要程度有区别)、管理需求(因特行的管理目的)或使用需求(与其他数据之间使用范围 / 目的不同)等进行数据分类,进而得到数据一级分类,形成数据表、数据项、数据文件等不同的组合。一级子类划分完成后,按照组织实际需求进行下一步细分,数据细分流程及示例如下图所示。
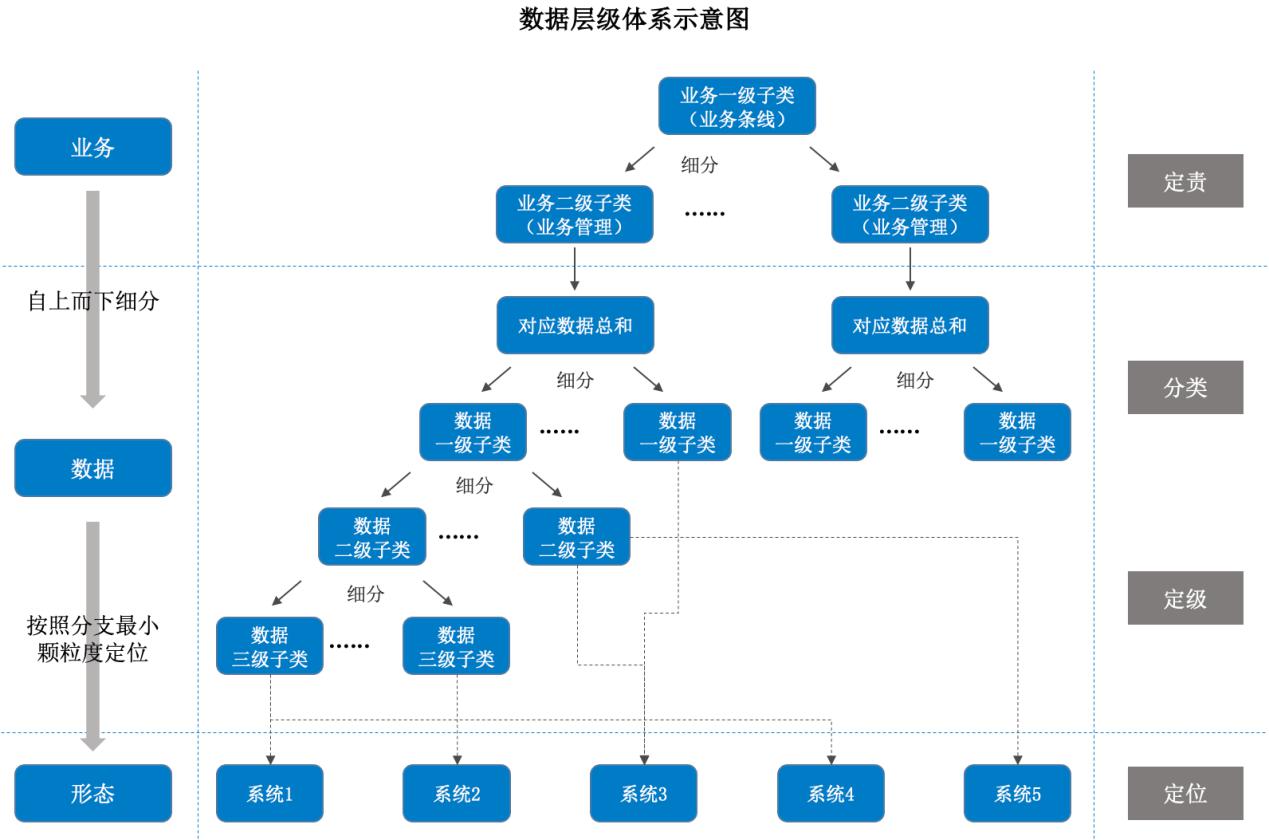
图 3 数据层级体系示意图
数据分级影响因素较多,包括数据影响对象、影响范围、影响程度等,并且需结合数据体量、数据聚合、数据实效性等进行综合分析,完成数据定级。目前,医院数据分级方法是基于数据的敏感性、风险防控、等级保护等,并结合自身情况,进行数据分级。

图 4 数据分级影响因素图
(5)数据分类分级落地运营:通过智能识别 + 人工审核的方式,根据预先策略智能化处理分类分级标签,可视化呈现分类分级结果,并支持自定义修改标准,整体实现数据分类分级工作闭环。一般步骤如下:
1)内置数据分类分级策略:一般从业务类型、分类分级策略、数据字典等维度展开。
2)数据分类分级:执行阶段有工具自动分类分级、人工达标、结果确认、任务执行监控等。
3)数据分类分级结果展示:主要生成数据分类分级结果清单和报告。
4.6 成果和价值
通过数据分类分级管理,江苏省人民医院进一步有效使用和保护了院内数据,数据存储、使用、共享等更易满足风险管理、合规性和安全性等要求,实现对不同类别和不同敏感级别数据的差异化管理和安全保护。综合来看,医疗行业数据分类分级的价值体现有:
1、满足合规要求:合规性是医院平稳运行的基本要求,通过采用流程和技术手段落实数据分类分级工作,既方便医院对数据实施针对性保护措施,又可加强对数据隐私保护,满足数据合规要求。
2、形成数据资产地图,更好的管理和保护数据:通过梳理医院内部数据资源,明确数据存储位置、类别和敏感程度,形成医院数据资产地图, 帮助医院做好数据管理,减少数据维护成本。
3、提升数据使用价值:数据分类分级实现了医院数据资产的精细化管理,可持续为医院提供精准的数据服务,不断提高数据的使用价值。
4、提升业务运行效率,减少数据安全风险:采用规范的数据分类分级方法,可帮助医院厘清数据资产,针对性地采取适当合理的管理手段和安全防护措施,有效管理、保护、存储和使用医院数据资产,从而赋能业务运营,提升运营效率, 也可减少数据遭受篡改、破坏、泄露、丢失或非法利用的可能。
本文摘编自中关村网络安全与信息化产业联盟数据安全治理专业委会编著的《数据安全治理白皮书 5.0——医疗数据安全治理实践(医院实践篇)》。
在此声明以上观点和内容,仅代表原作者和出处,与数治网DTZed 无关,如有出错或侵害到相关合法权益,请通过电邮与我们联系:cs@dtzed.com。
在文末扫码关注官方微信公众号“idtzed”,发送“入”直通相关数治x行业共建群、AIGC+X 成长营,@老邪 每周免费领取法规、标准、图谱等工具包。
欢迎先注册,登录后即可下载检索分类分级等相关标准、白皮书及报告。更多高质量纯净资料下载,在文末扫码关注官方微信公众号“idtzed”,进入公众号菜单“治库”。