
在经济新常态下,银行正面临持续加深的市场化改革和互联网金融大潮的双重挑战。2019 年 11 月,党的十九届四中全会发布《中共中央关于坚持和完善中国特色社会主义制 度推进国家治理体系和治理能力现代化若干重大决定》,首次将数据列为生产要素,提出了鉴权劳动、资本、土地、只是、技术、管理、数据等生产要素由市场评价贡献、按贡献决定报酬机制。2022 年“数据二十条”发布,提出建设数据要素市场体系,重点需要完善数据基础制度,加强数据要素、数据产品的供给能力。
因此,为顺应数据发展趋势,响应国家号召,银行业需要尽快进行数数字化转型。而数字化转型的重点就是构建数据驱动的能力,需要从以下三个方面进行基本能力的建设:一是坚实的数据平台,二是完善的数据管理体系,三是高效的数据产品与应用开发能力。前两方面的建设日趋成熟,当前银行业数据能力建设的主要矛盾是旺盛的数据需求与数据生产力不足之间的矛盾。如何提升数据生产力,便是银行业建设的重要课题,也是 DataOps 体系建设的重要方向。
一、目标
数据研发工作站是北京银行基于微服务架构自主研发的一站式数据开发运营 DataOps 平台。该平台的总体目标是建立高效数据智能研发运维流水线,在数据研发运营过程中降成本、增能效、提质量,促进自主掌握。
1. 敏捷开发与交付
- 全生命周期敏捷开发,实现需求、调研、设计、开发、测试、投产、运维一站式线上化数据敏捷开发;
- CICD 流水线持续交付, 对接行内 DevOps 一站式研发流程平台,打通制品晋级流程,实现持续集成,持续部署,持续交付。
2. 开发治理一体化
- 数据标准融入开发流程,对接全行企业级数据字典,实现模型设计、数据质量、数据安全模块接入数据标准;
- 数据开发与元数据联通,对接元数据管理系统,实现数据源管理、模型设计、脚本开发、数据测试过程与元数据互联互通。
3. 高效协同与资产共享
- 协同数据开发,通过平台共享功能,支持跨团队、跨项目协同开发,降低线下沟通问题、提高协作效率;
- 自助服务与共享,沙箱自助探索、资产中心资产共享,实现数据全生命周期的洞察、分析、共享,提升数据使用价值。
4. 精细化数据运营
- 统一规范与管理,制定统一的模型设计及开发规范,沉淀多种需求、调研、设计、开发、测试及上线清单模板,打通数据交付全生命周期,形成标准化数据交付流水线;
- 全链路度量与反馈,提供数据全生命周期度量评价指标,提供全链路血缘分析功能,支持各系统异常任务的快速定位以及影响分析。
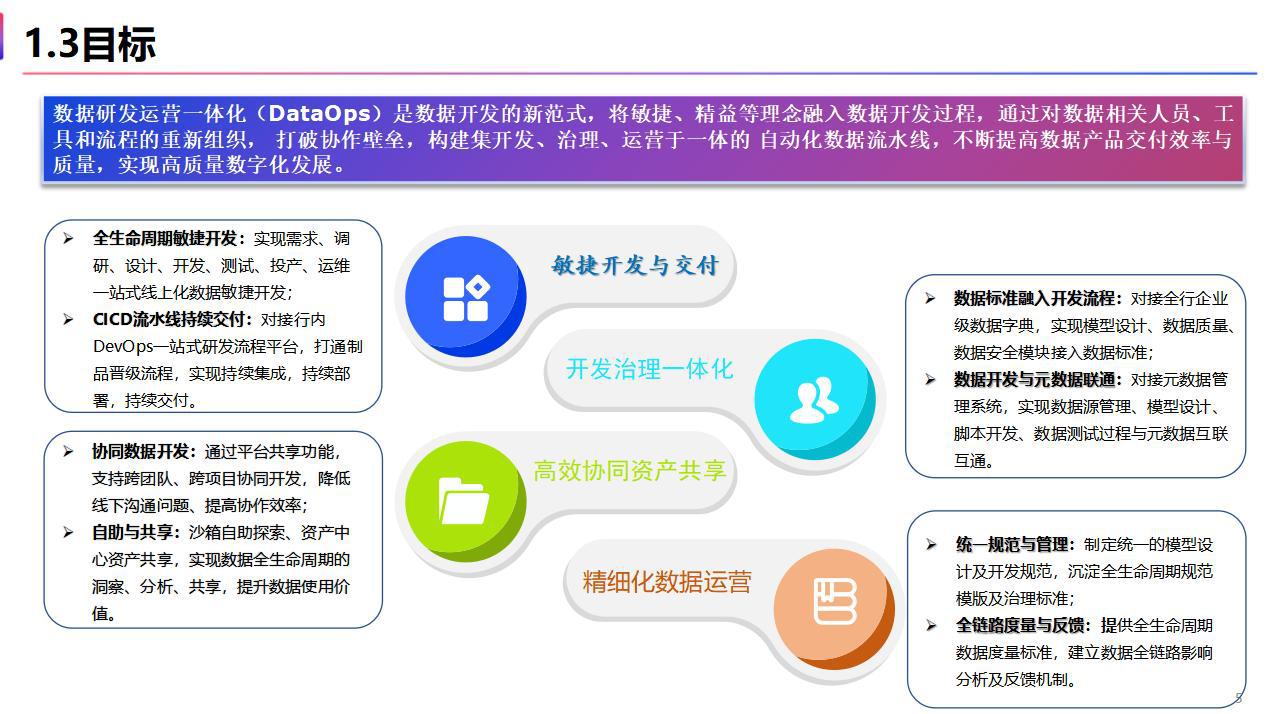
图 1 DataOps 建设目标
二、DataOps 建设体系
我行数据研发工作站功能覆盖数据研发、交付和运营全生命周期,包括任务管理、数据调研、模型设计、数据同步、数据开发、数据测试、一键部署、运营监控。各环节特点如下:
- 任务管理:对接行内 DevOps 一站式研发流程平台,打通需求条目细化到开发任务的整个流程;接收 DevOps 下发的数据研发任务,支持任务关联数据开发成果,提供任务管理看板,支持任务状态的监控和跟踪。
- 数据调研:支持源系统调研、入湖调研以及业务调研功能;统一数据调研模板,支持表级和字段级调研结果的维护,支持项目组间共享调研结果。
- 模型设计:对接数据资产管理平台, 支持逻辑模型版本管理,提供逻辑模型转物理模型的功能;对接企业级数据字典,支持物理模型引用数据标准,提供模型层及主题层落标情况检查,生成落标报告查看贯标结果;支持线上模型设计,以及模型映射模板的导入导出;支持模型的审核和发布。
- 数据同步:提供数据同步导入模板, 支持自动化解析生成同步任务;提供文件与文件、文件与表以及表与表之间相互同步功能, 支持单表同步以及多表同步任务,实现数据流量控制。
- 数据开发:对接元数据管理平台,支持贴源基础数据的自动入湖;支持根据模型映射自动生成数据加工 ETL 程序,支持程序的线上调试和修改;支持调度程序的配置化开发; 提供数据探索功能,可查看各系统数据源库表结构,支持 DDL 语句、DML 语句、存储过程、函数等在线 IDE 执行。
- 数据测试:对接行内测试管理平台, 支持包括唯一性、空值率、主外键校验、长度校验、自定义规则校验等单元测试,支持执行并自动生成测试案例及测试报告。实现自动化数据准备、自动化数据检查、测试案例沉淀。
- 一键部署:对接行内统一代码版本管理工具,支持程序自动化打包和版本管理;支持在一键部署页面配置数据源,自动执行入湖脚本、同步脚本、建表脚本、ETL 脚本等,减少人工处理环节,提高交付效能。
- 运营监控:对生产环境进行数据量监控、文件监控、作业监控以及全链路监控,支持查看数据湖、共性数据处理平台以及各数据集市的资产运行情况;支持查看作业上下游依赖运行情况,便于各系统异常作业排查及影响分析。
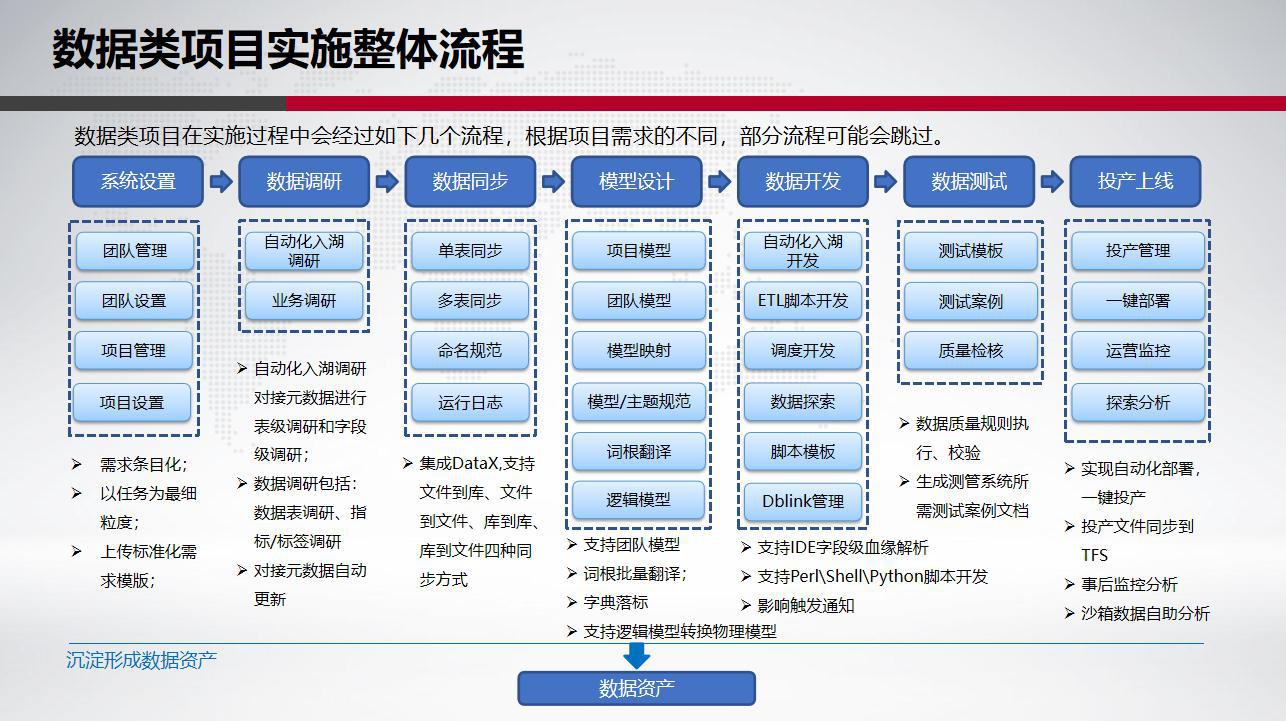
图 2 DataOps 建设体系
2.1 应用方案
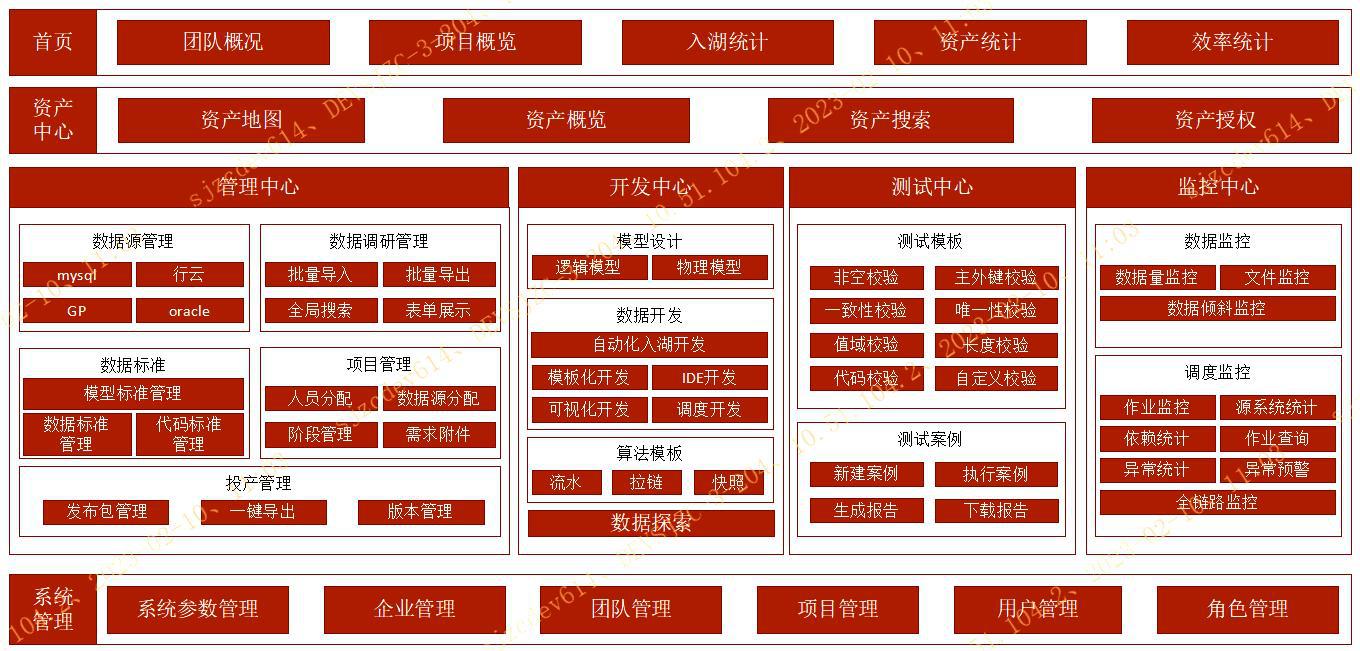
图 3 数据研发工作站应用方案
数据研发工作站是面向行内数据底座的数据加工,服务于相应区域的模型人员、开发人员、及总分行科技人员。通过创建稳定的交付体系,实现数据交付过程的标准化和自动化,提升交付质量和交付效率。
2.2 技术方案
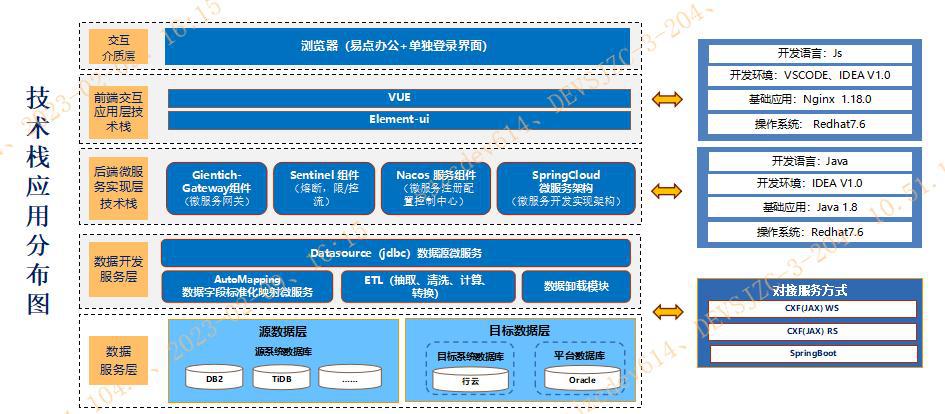
图 4 数据研发工作站技术方案
在总体技术方案设计上,数据研发工作站遵循行内统一顺天技术平台技术规范,采用微服务的架构,利用一致的可共享的数据模型,致力于提高系统的灵活性、可扩展性、安全性以及并发处理能力。
三、应用实践
北京银行 DataOps 建设,将数据从需求到结果的全部流程实现线上化,在数据采集、数据入湖、投产部署等关键环节实现“零代码”,推广零售数据集市、对公数据集市、监管数据集市等 18+ 数据处理系统进行全生命周期开发使用,沉淀了 60+ 项目、2000+ 调研、5000+ 入贴源层、1500+ 数据模型、2000+ 存储过程、90+ 投产数等,有效促进了流程标准化、交付自动化、开发线上化、资产可视化,交付效能提升 50% 以上。
.jpg)
图 5 数据研发工作站应用实践(总行)
将敏态数据研发模式推广至 17 家分行,总分一体提升数据交付能力,在研发过程中持续将组织过程资产进行留存和共享,数据标准、数据调研、元数据、数据模型等信息实现了企业级共享,保证信息一致性、也减少了重复沟通的成本。
.jpg)
图 6 数据研发工作站应用实践(分行)
四、展望
1. 提升智能化能力
通过引入大数据、人工智能技术,支持对脚本的模拟和训练、自动化建模与脚本开发,增强数据研发过程的自动化和智能化;同时数据中台的智能化功能,还可以对数据质量的实时监控和预测,系统可以自动检测数据质量异常,并提供智能化的预测分析,帮助用户及时发现和解决数据质量问题,从而提高数据的准确性和可靠性。
2. 构建协同共享能力
建立与数据生态系统中的合作伙伴的紧密合作关系,包括数据供应者、数据消费者、数据服务提供者等。通过共享数据和资源,实现数据生态系统的协同发展,共同推动运营体系的优化和创新。通过建立一个协同、高效、可持续发展的数据生态系统,为运营体系提供强大的支持和增值。
3. 加强精细化运营能力
对于数据研发全生命周期进行阶段指标的度量,及时评估与度量各个阶段的开发质量与效率,持续发现问题,反馈问题、解决问题,有效促进整个交付链路的运营能力;通过多维度运营监控,实时监控系统状态、及时发现问题,快速排出故障和系统优化。研发、评价和反馈的闭环治理方式,不断提升行业内大数据领域的数据服务能力成熟度。
数据是上述各能力发挥效用的土壤,随着数据源越来丰富,数据使用场景越来越多元, DataOps 将会融合更多新兴技术,释放更多能量。
作者:北京银行股份有限公司 张碧佳、张佳慧
欢迎平台、工具、应用及案例入库、发布和召募推广,立即订阅数字推广DigiPacks 套餐,我们的目标是潜在客户,扫码添加老邪企业微信:


-228x171.jpg)
