
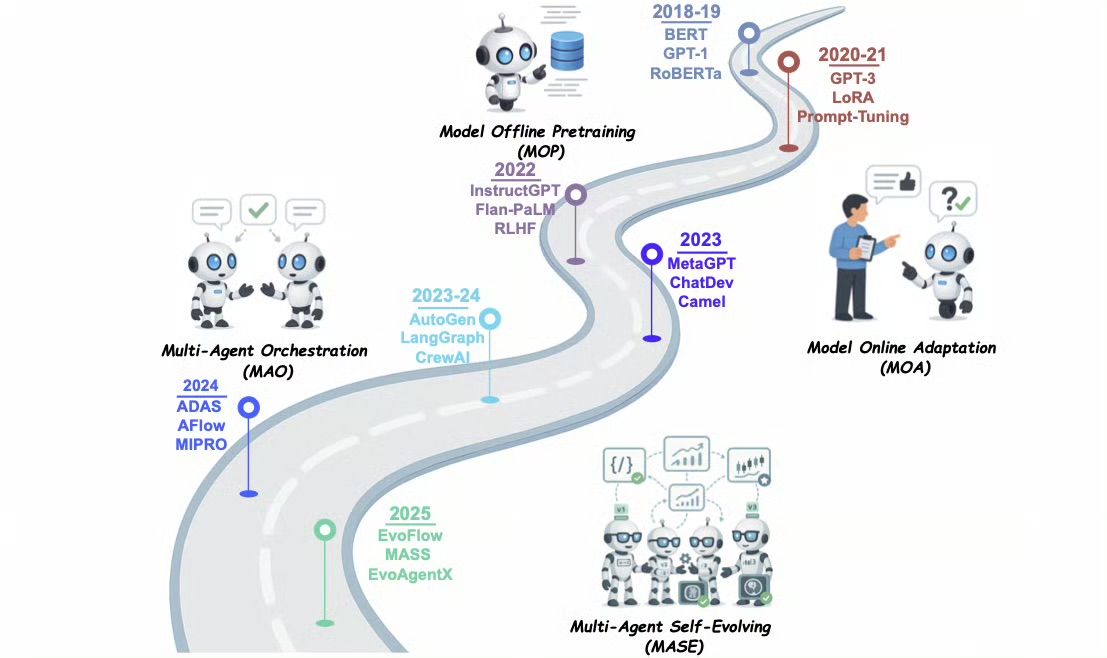
2018年,大模型像一本不会翻页的百科全书。2021年,它学会开口,却仍要等人提示下令。2023年,一群大模型开始组队,像剧组一样分工。2025年,剧组里自己分饰角色,当导演、当编剧、当观众,一出独角戏边演边改。
七年一瞬,变化看似眼花缭乱,本质只有一条:把“人告诉机器要做什么”变成“机器告诉人下一步该怎么做决定”。剩下的,是人与机器共同写下一幕更长、更复杂的戏。
一、时间线速览
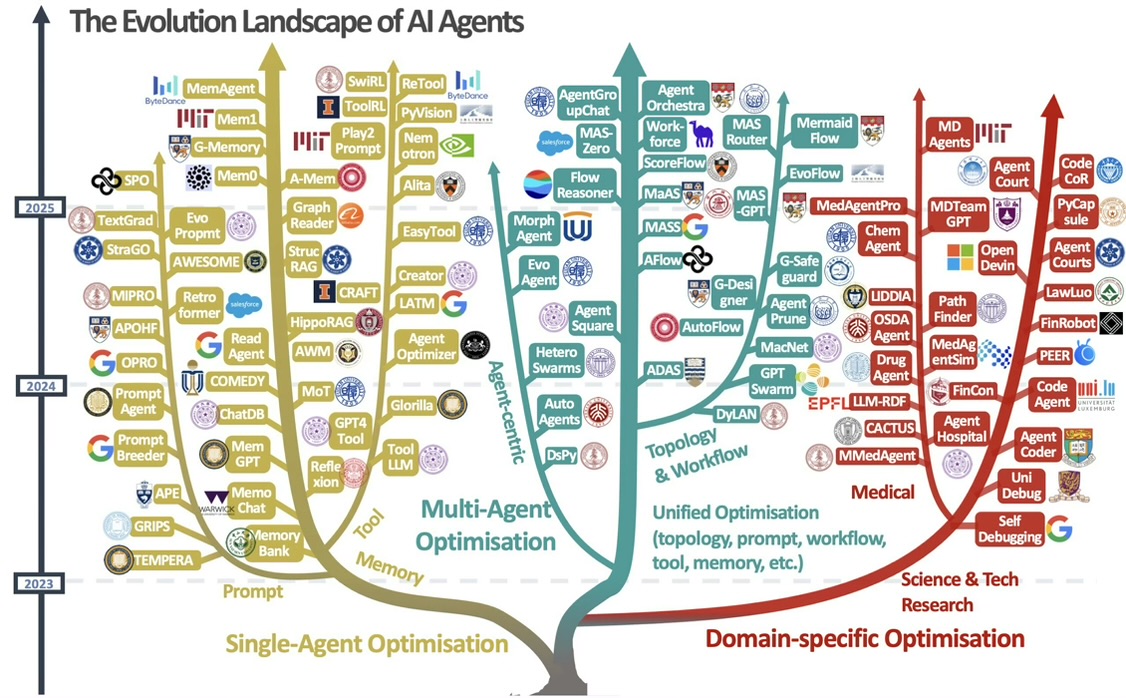
2018-2019 • 单智能体离线预训练:BERT、GPT-1、RoBERTa——只有模型权重,没有记忆与工具
2018年,人们第一次见到BERT。它像刚入学启蒙的学生,把整本百科全书背得滚瓜烂熟,还不会开口。同年,GPT-1诞生,更像一位沉默的诗人,肚子里有词,却不知道怎么造句,更别说动听。
那一两年里,大家把模型训练当成“闭关修炼”:先离线苦读,再上线考试,成绩好坏全靠事先死记硬背。
2019-2020 • 提示词工程萌芽:Prompt-Tuning、LoRA——人类手动改提示
BERT被RoBERTa替换,GPT-1也长成GPT-3。参数变多,书背得更厚,考试分数也更高,可它们依旧不会主动做事。研究人员只能把“提示”当成一句句咒语让大模型写出答案。提示调优、LoRA、Prompt-Tuning 这些工具,本质是让指令更精准,只不过遥控器在人手里。
2020-2021 • RLHF引入:InstructGPT、Flan-PaLM——提示词开始由人类反馈优化。
• 任务粒度细化:单一问答 → 多步推理,但仍属单智能体。
InstructGPT 和 Flan-PaLM 把“人类反馈”塞进训练流程。大模型像被老师手把手教了一遍,终于听懂“请用礼貌语气回答”这类要求。RLHF(人类反馈强化学习)成了关键杠杆:先让人打分,再让大模型学着拿到高分。
离线预训练(MOP)爬到天花板。模型再大,也跟不上世界每天的新信息和变化。研究人员意识到,必须让模型上线后还能继续学,于是“在线适应”成为新课题:考完试还要继续苦读,而不是把书合上。
2023 • 多智能体元年:MetaGPT、ChatDev、Camel、AutoGen、LangGraph——出现“拓扑”概念
• 领域智能体初现:MedAgentPro、FinRobot、LawLuo
MetaGPT、ChatDev、Camel、AutoGen、LangGraph 像一个个小分队,把“写代码、画流程、做测试”拆给不同角色。有的当架构师,有的当码农,有的当测试:它们用消息、拓扑、记忆彼此沟通。这一年,关键词从“单智能体”跳到“多智能体编排”(MAO)。
2023-2024 • 编排层细化:CrewAI、ADAS、AFlow、MIPRO——拓扑、提示词、工具、记忆全部可在线调整
• 记忆共享:ChatDB、MemAgent、G-Memory
• 工具生态:EasyTool、ChemPrompt、ToolRL
CrewAI、ADAS、AFlow、MIPRO 把“编排”拆成更细的工种:谁负责找工具,谁负责改提示,谁负责记笔记。系统开始自带“优化器”,像有导演一样喊停、重来、换演员。研究人员不再手动调提示,而是把遥控器交给另一个智能体去调。
2025 • 自我进化:EvoFlow、MASS、EvoAgentx——系统可在任务结束后自动重排拓扑、重写提示、增删工具、压缩记忆。
EvoFlow、MASS、EvoAgentx 把多智能体系统变成“内功心法”:任务做完,系统反思哪里做得不足,下一次自动换一种拓扑、换一套提示、甚至换掉用的工具。这种“多智能体自我进化”(MASE)标志着修炼从“上山拜师”升级到“下山悟道”。
二、三条主线:任务粒度、记忆、工具
回望七年,变化可用三条主线串起来,从整卷考试到随堂测验任务,从金鱼的记忆到时刻备忘,从赤手空拳到随身携带瑞士军刀。
1、任务粒度
2018年,一次任务等于一整张卷子。2023年起,卷子被改成无数小测验:写标题、查文献、画图表、改格式。粒度变细,错误才能被精准定位、快速修复。
2、记忆
早期大模型像金鱼,七秒就忘。2023年,ChatDB、MemAgent、G-Memory 把聊天记录、中间结果、外部知识统统塞进“集体备忘录”。记忆不再只属于单智能体,而成为整个小分队的共享仓库。
3、工具
2018年,大模型只能动嘴。2022年后,ToolRL、EasyTool、FinRobot、MedAgentPro 让模型学会调用搜索引擎、运行代码、查询数据库。工具箱公开透明,任何智能体都能按需取用。
优化路线对照表
| 时期 | 类别 | 拓扑 | 提示词 | 工作流 | 工具 | 记忆 |
|---|---|---|---|---|---|---|
| 2018-2019 | 单智能体 | 无拓扑(单节点) | 人工一次性模板 | 单步问答 | 无 | 无持久记忆 |
| 2020-2021 | 单智能体 | 仍单节点 | 人工微调(Prompt-Tuning/LoRA) | 多步推理链 | 无 | 仍无持久记忆 |
| 2022 | 单智能体 | 单节点+链式自回归 | 人类反馈强化学习 RLHF | 链式CoT | 无 | 会话级缓存 |
| 2023 | 多智能体 | 星型/链型拓扑(ChatDev、AutoGen) | 各角色独立提示,人工编排 | 角色-子任务-合并 | 公共工具注册表(EasyTool) | 共享记忆仓库(ChatDB) |
| 2023-2024 | 多智能体 | 可演化拓扑(LangGraph、CrewAI) | 自动提示优化器(MIPRO) | 运行时拓扑重排 | 工具调用策略学习(ToolRL) | 可读写长期记忆(G-Memory) |
| 2025 | 多智能体 | 在线变异拓扑(EvoFlow、MASS) | 自我重写提示模板 | 闭环反思-再执行 | 工具库自我增删 | 记忆压缩-检索双模块 |
| 2023 | 领域智能体(法律) | 链式:检索-推理-写作 | 领域提示库(LawLuo) | 合同条款流水线 | 法规、判例API | 案件记忆树 |
| 2023-2024 | 领域智能体(医疗) | 星型:化学-生物-法规 | 医学Prompt模板(MedAgentPro) | 药物发现管线 | 化合物、副作用DB | 病人病例共享记忆 |
| 2024 | 领域智能体(金融) | 网状:新闻-行情-风控 | 交易Prompt模板(FinRobot) | 实时对冲工作流 | 行情、财报API | 市场事件记忆流 |
| 2025 | 领域智能体(科研) | 自适应拓扑(EvoAgentx) | 自我演化科研Prompt | 实验-复现-写作闭环 | Python、仪器接口 | 实验数据长期存储 |
来源:数治网
说明:
- “拓扑”指智能体之间的连接结构;单智能体阶段为空。
- “提示词”从人工模板 → 人类反馈 → 自动优化 → 自我重写。
- “工作流”从单步 → 链式 → 角色分工 → 在线重排 → 闭环进化。
- “工具”从缺失 → 公共工具表 → 工具策略学习 → 工具库自生。
- “记忆”从会话级 → 共享仓库 → 长期压缩 → 领域记忆树/流。
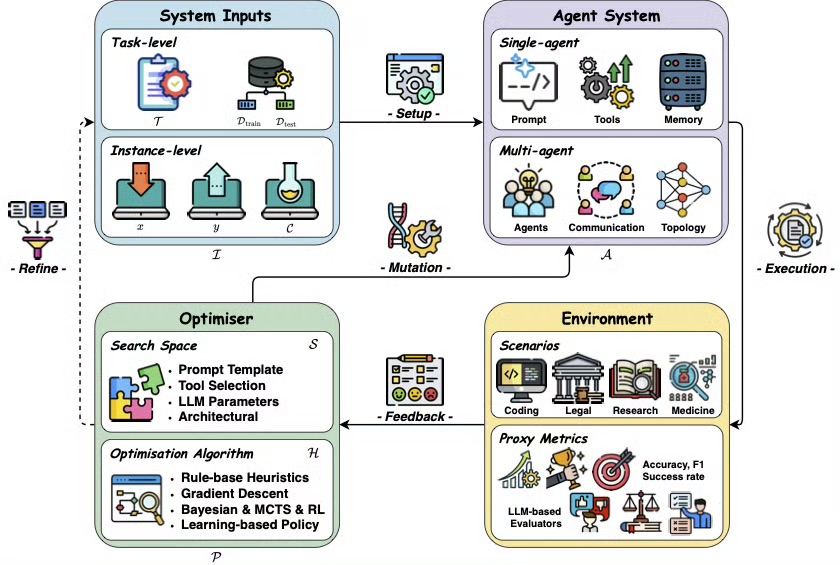
4、系统视角
今天,一个完整的智能体系统的输入、演化、输出像一家小型公司。
输入端:任务描述、外部知识、可用工具、过往记忆。
系统内部:
- 先由“优化器”决定谁是牛马,谁当领导;
- 接着,智能体之间按既定拓扑通信:链式、星型、网状,随场景切换;
- 每一步都可变异:提示模板、工具选择、甚至拓扑结构都能在线调整;
- 环境实时反馈:成功、失败、用户评分、代理指标,如F1值、成功率、规则命中率;
- 反馈被喂给贝叶斯搜索、强化学习或基于大模型的策略,系统像生物一样突变、筛选、保留优势基因。
输出端:代码、合同、诊断报告、实验方案……随领域而变,但共同点是——输出本身又成为下一轮输入,闭环不休。
三、领域故事:四个切片
1、法律
2023年以前,律师要花三小时审一份合同。2024年,LawLuo 把合同拆成条款,让“检索智能体”找先例,“推理智能体”标风险,“写作智能体”生成修改意见。人类律师只需在最后签字。系统上线三个月,律所把初级律师的加班时间砍掉一半。
2、医疗
MedAgentPro 带领一群“化学智能体”“生物智能体”“法规智能体”共同研发新药。化学智能体提出分子结构,生物智能体模拟副作用,法规智能体检查是否符合FDA格式。过去需要六个月的预研报告,现在两周生成初稿,留给人类专家的是更高阶的创意判断。
医疗领域智能体
多智能体系统的拓扑靠“剪枝+联合微调”自动优化,在医疗场景里,它们从靶点到病床全程协作,把重复劳动留给机器,把决策权与同情心留给人类。
| 阶段 | 参与智能体 | 拓扑 | 工具 | 记忆 | 输出 |
|---|---|---|---|---|---|
| ①靶点发现 | 文献检索体+基因挖掘体+专利监控体 | 星型:基因体为中心 | PubMed API、Ensembl、专利库 | 共享知识图谱(基因-疾病-化合物) | 高置信靶点列表 |
| ②分子设计 | 化学生成体+ADME预测体+毒性辩论体 | 链式:生成→预测→辩论→再生成 | 分子模拟软件、毒性数据库 | 分子-性质记忆表 | 候选化合物 Top10 |
| ③临床前 | 法规检查体+实验规划体+预算审计体 | 并行三轨 | FDA Guideline API、LIMS系统 | 试验方案历史库 | 可执行的动物/细胞实验计划 |
| ④患者招募 | 电子病历体+招募匹配体+伦理审查体 | 星型:病历体为中心 | 医院HIS、患者App | 匿名化病历池 | 合格受试者清单 |
| ⑤诊疗辅助 | 诊断体+影像体+用药建议体+患者教育体 | 链式+反馈环 | PACS影像系统、药物相互作用库 | 患者时序健康档案 | 诊断报告+个性化用药方案 |
安全与可控措施:
- 每一步输出都写入不可篡改日志,供药监局审计。
- 涉及患者数据时,先由隐私过滤体做去标识化,再进入共享记忆。
- 关键决策(用药剂量、试验终止)必须经人类医生二次确认,系统只给推荐。
来源:数治网
3、金融
FinRobot 连接实时行情、财报数据库与新闻流。早上八点,系统读完隔夜新闻,九点钟给出三支可能跳水的债券,十点钟自动为交易员生成对冲方案。它不只是提醒风险,还直接给出可执行的交易指令。人类交易员从“盯盘”变成“盯策略”。
4、科研
2025年,一个生物学实验室引进 EvoAgentx。学生只需输入一句“我想看懂这篇关于CRISPR的新论文”,系统立刻派出“文献检索智能体”下载论文,“背景补充智能体”查找基础概念,“实验复现智能体”用公开数据跑一遍图表。
之后,学生收到一份带注释的论文和可运行的Jupyter Notebook。科研入门门槛被削掉一大截。
四、未来三问
1、会不会失控?
自我进化意味着系统可以修改自身代码。目前的安全阀有三道:
- 沙箱:任何修改先在隔离环境试运行。
- 规则基线:关键操作必须满足硬编码规则,否则自动回滚。
- 人类否决权:重要决策留给人拍板,系统只能建议不能擅动。
这三道锁,短期内不会被同时解开。
2、人类还剩什么?
当系统会查资料、会写代码、会改提示,人类的比较优势只剩下三件事:
- 提出好问题——因为目标函数仍由人设定。
- 承担最终责任——法律与伦理不能借助外脑。
- 审美与创意——系统能模仿风格,却难创造新风格。
3、下一步往哪走?
眼下,智能体主要活动在数字世界。下一批挑战是让它们走进物理世界:控制机械臂、驾驶卡车、管理农田。那需要新的传感器、新的安全协议、新的实时操作系统。进化不会停,但节奏会从“每月发布新版本”变成“每秒在线微调”。
“老邪说”专栏系列:
- 人机协作:当你的AI助手总“已读乱回”,你还Vibe不Vibe?
- 《超4000亿!美国AI初创公司融资流向、赛道与逻辑全曝光(附一览表)》
- 《“小而美”改成“快而赚” 复刻小团队从0打造4000万营收AI爆款》
来源:网络,本篇结合生成式 AI 做出的核心摘要和解答,仅作为参考。图片:Solen Feyissa,Unsplash
碎片化学习,上 shuzhi.me !数智有你,一课开启:
- 一听微课堂破解“学用脱节”:留存率能做到81%
- 二问微学习培养“即插即用”:完课率能达到78%
- 三维微专业实现“产研融合”:在2周内完成迭代
所有课件、题库、问答基于海光认证iDTM+DeepSeek R1应用生成。免改免维云上多端AI透明化终身学习,现在我的台我来站!
更多有关模块课程、配套工具、框架问卷、服务矩阵以及整改案例等数治Pro一站式治理,欢迎扫码入群 @老邪 了解、获取。


一条评论