在当今数字时代,数据成为推动技术创新和商业决策的重要驱动力。然而,许多行业面临着数据获取不足、质量不高以及数据样本不平衡等挑战。随着人工智能技术的迅速发展,生成式人工智能驱动数据技术正在崭露头角,为数据处理和分析领域带来了一系列创新解决方案。
在不同的领域和行业中,对于海量数据的定义有所不同。一般来说,“海量数据”(Massive Data)是指数据量大到用传统的数据管理和处理技术难以有效存储、管理和分析的数据集合。而海量数据处理技术,并非特指某一项技术,而是为了满足业务和行业实际需求的综合性解决方案技术栈,帮助金融机构充分利用数据,更加轻松地挖掘分析数据价值。
一、海量数据处理技术框架与形态
1. 海量数据处理技术基本形态
从外部形态上,海量数据处理技术需具备类 SQL 交互语言支持、Python 语言支持、常用如 Flink、Spark 等计算引擎支持,保持标准开放性,主要支持从 TB 至百 PB 级别的数据处理能力,延展至 EB 级数据能力规模,以应对当下和未来的持续挑战,支持存算分离,以实现按需配置,最终实现性能、需求、成本、易用性、灵活性的平衡等。如图 1 是一个典型的海量数据处理技术架构:

图 1 典型的海量数据处理架构
2. 分布式存储框架
海量数据的存储通常基于分布式文件存储或对象存储,支持水平扩容,支持多种存储数据类型,提供结构化、半结构化、非结构化数据的存储解决方案。目前常用的存储框架,主要以文件 存储、列式存储、对象存储三大类为主,属于图 1 的“分布式存储管理”模块,基本覆盖包括金融业在内的主要存储场景,这三者存储类型同属于大数据技术栈的底层存储层,但满足的是不同场景的存储需求,是金融业海量数据处理环节中的第一步。
HDFS(Hadoop Distributed File System,HDFS)是面向 PB 级数据存储的分布式文件系统,可以存储任意类型与格式的数据文件,包括结构化的数据以及非结构化的数据。HDFS 将导入的大数据文件切割成小数据块,均匀分布到服务器集群中的各个节点,并且每个数据块多副本冗余存储,保证了数据的可靠性。HDFS 还提供专有的接口 API,用以存储与获取文件内容。
Ozone 是大数据场景中融合文件系统和对象存储的较佳解决 方案,能有效解决用户在使用过程中各类存储需求,并延续 Hadoop 开源存储项目的存储成本优势。生态方面支持 Hadoop 文件系统、对象存储/S3、本地路径挂载和 K8S CSI 等多种访问方式。Ozone 与 Hadoop 生态融合,如 Apache Hive、Apache Spark 等无缝对接。Ozone 支持Hadoop Compatible FileSystem API (aka OzoneFS)。通过 OzoneFS, Hive,Spark 等应用不需要做修改,就可以运行在 Ozone 上。除此之外,Ozone 还同时支持数据本地化,使得计算能够尽可能地靠近数据。
HBase 是一个构建在 HDFS 上的分布式存储系统,主要用于海量结构化数据存储。从逻辑上讲,HBase 将数据按照表、行和列进行存储。与 HDFS 一样,HBase 目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。一方面, HBase 能够支持灵活的列字段定义;另一方面, HBase 利用LSM(Log-Structured Merge-Tree,LSM)数据结构模型,将数据的随机访问转换成对磁盘的顺序读写,从而实现高性能的数据随机访问。HDFS 节点主要负责 HBase 底层存储,HDFS 保证了 HBase 的高可靠性。HDFS 为 RegionServer 和 Master 节点提供分布式存储服务,同时保证数据的可靠性。HBase 的架构如图 2 所示:
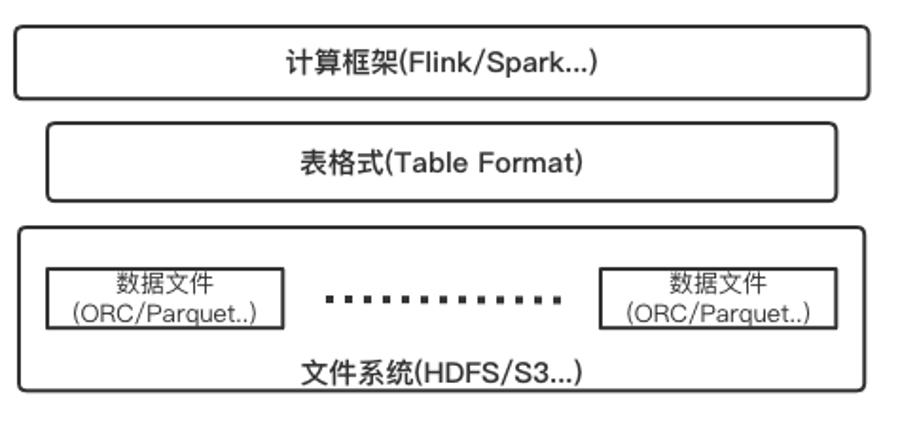
图 2 HBase 分布式存储架构
3. 数据组织方式与分析技术框架核心
Iceberg 是一个面向海量数据分析场景的开放表格式(Table Format),有时也被认为是新一代的数据湖仓组件。定义中所说的表格式(Table Format),可以理解为元数据以及数据文件的一种组织方式,处于计算框架(Flink,Spark…)之下,数据文件之上。
表格式(Table Format)属于数据库系统在实现层面上的一个抽象概念,一般表格式会定义出一些表元数据信息以及 API 接口,比如表中包含哪些字段,表下面文件的组织形式、表索引信息、统计信息以及上层查询引擎读取、写入表中文件的接口。
4. 数据编排与缓存加速核心
Alluxio 被认为是一种数据编排技术。它为数据驱动型应用和存储系统构建了桥梁,将数据从存储层移动到距离数据驱动型 应用更近的位置从而能够更容易被访问。在海量数据处理生态系统中,Alluxio 位于数据驱动框架或应用(如 Apache Spark)和各种持久化存储系统(如 HDFS)之间。Alluxio 统一了存储在这些不同系统中的数据,为其上层数据驱动型应用提供统一的客户端 API 和全局命名空间。
5. 消息队列
消息队列支持亿级的消息接收、中转和推送服务,可弹性扩展,无并发限制,高性能具备低延迟、高并发、高可用、高可靠等特性,可支撑亿级数据洪峰的分布式消息中间件,无缝迁移, 更安全、更可靠、更易运维。
6. 分布式计算框架与分析引擎
Hive 把存储在 HDFS 之上的结构化数据抽象成关系型数据表, 并提供 SQL 接口对数据表做查询操作。因此,用户能够以传统关系型数据库的方式来查询大数据存储系统,可以通过 Hive 来实现SQL 查询分析。
Flink 提供高吞吐量、低延迟的流数据引擎以及对“事件- 时间”处理和状态管理的支持。Flink 应用程序在发生机器故障时具有容错能力,并且支持 exactly-once 语义。程序可以用 Java、Scala、Python 和SQL 等语言编写,并自动编译和优化集群或云环境中运行的数据流程序。此外,Flink 的运行时本身也支持迭代算法的执行。
Tez 是一种支持 DAG 作业的开源计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升 DAG 作业的性能,相对于原始的MapReduce 框架,Tez 可以一次Map 读取,多次 reduce 操作而中间不用进行 IO 操作,从而降低频繁的文件 IO 和网络IO,相对MapReduce,使用TEZ 做计算引擎性能能提高很多。
Spark 是一种海量数据并行计算框架,充分利用集群的内存资源来分布数据集,大幅提高计算性能。Spark 包含丰富的计算生态,包括 SparkSQL、MLlib 等。Spark 支持丰富的编程语言如: Scala、Python、R、Java 等等。
Presto 是一个分布式 SQL 查询引擎,适用于交互式分析查询,数据量支持 GB 到 PB 字节。Presto 的设计和编写主要是为了解决 PB 规模的海量数据交互式分析和处理问题。同时,Presto支持多种数据源,比如 Accumulo,HDFS,Redis,PostgreSQL, MySQL 等,支持多数据源 JOIN 查询。
二、生成式人工智能驱动数据技术
生成式人工智能是一类人工智能模型,其主要目标是生成新的数据样本,这些样本与训练数据类似。生成模型通过学习训练数据的潜在分布和特征,能够生成逼真的图像、音频、文本等。 其中,Transformer 模型和GANs(生成对抗网络)是生成式人工智能的代表性模型。
1. 数据增强与样本生成
数据增强是利用生成模型合成新的数据样本,从而增加训练数据的多样性,改善模型的泛化能力。在自然语言处理领域,通过生成式语言模型,可以轻松地生成大量与原始数据类似的句子,从而扩充数据集。在计算机视觉中,生成式模型能够生成具有各种变换和扰动的图像样本,有效提高了模型的鲁棒性和准确性。
此外,生成式人工智能也可以用于样本生成。在医疗影像诊断中,数据收集是一项耗时且昂贵的任务。通过使用生成式模型,可以合成大量的医疗影像数据,帮助加速医学图像处理和疾病诊断的研究进展。
2. 数据清洗和修复
数据质量是影响人工智能模型性能的一个重要因素。然而,现实中的数据往往会受到噪声、缺失或错误等问题的影响。生成式人工智能为数据清洗和修复提供了新的解决思路。
生成式模型可以学习数据样本的分布规律,进而自动纠正损坏或缺失的数据。例如,在自然语言处理任务中,模型可以通过生成合理的上下文信息来修复错误或缺失的单词或短语。这种技 术在提高文本数据质量和减轻数据预处理负担方面具有巨大潜力。
3. 数据合成与扩充
在某些应用场景下,真实数据难以获得,或者可能涉及隐私或版权问题。生成式人工智能提供了一种安全且有效的方式来生成合成数据,以替代真实数据进行模型训练或测试。 在自动驾驶技术开发中,生成式模型可以生成大量虚拟驾驶场景,用于测试自动驾驶系统的稳定性和安全性,而不必依赖于真实道路测试,从而降低了测试成本和风险。
4. 自动数据标注
数据标注是训练监督学习模型所必需的,但通常需要大量的人工劳动。生成式人工智能技术为自动数据标注提供了新的解决方案。 通过结合生成式模型和半监督学习方法,我们可以自动生成标注数据,从而减轻了人工标注的负担。例如,在图像分类任务中,生成式模型可以自动给图像生成标签,从而用于训练分类器。
5. 生成数据模型与查询语句
通过接入最全面的企业内部数据源及数据资产元数据目录,内部数据模型由提示词驱动 AIGC(Artificial Intelligence Generated Content,AIGC),查询结果由 LLM(Large Language Model,LLM)进行解读分析,构建由业务需求及即席查询需求驱动的抽取建模。整个过程包括业务模型分析、自动生成数据模型、规划查询步骤、生成查询并执行、查询结果判读、多次迭代或并行执行进行分析探索。
三、海量数据处理技术应用展望
金融业一直都是大数据、人工智能等各种前沿技术理想的试验田,金融业积累的海量数据可以供从业人员不断测试、优化、完善各类新兴技术,并同时挖掘、探索金融业新的使用场景,进一步赋能金融业的创新和发展。未来海量数据处理技术对金融业的发展具有重要意义。
- 一是提高决策能力:海量数据处理技术可以帮助金融机构更好地理解和利用数据,从而提高决策的准确性和效率。通过分析大量的历史数据和实时数据,金融机构可以更好地预测市场趋势、评估风险和发现投资机会,这将帮助投资者做出更明智的决策,提高投资回报率。
- 二是优化风险管理能力:海量数据处理可以帮助金融机构更好地识别和管理风险。通过分析大量的数据,金融机构可以更准确地评估风险,并采取相应的措施来降低潜在的风 险。这将提高金融机构的稳定性和可持续性。
- 三是增强个性化服务能力:海量数据处理技术可以帮助金融机构更好地了解客户需求和行为模式。通过分析客户数据,金融机构可以提供更个性化的金融产品和服务,满足客户的特定需求,提高客户满意度和忠诚度。这将帮助金融机构在竞争激烈的市场中获得竞争优势。
- 四是提高交易效率:人工智能和海量数据的算法等技术可以帮助金融机构更快速地处理和分析大量的交易数据。通过提高交易速度和决策效率,金融机构可以降低交易成本,提高交易效率和利润。这对于高频交易和算法交易尤为重要。
本文摘编自北京金融科技产业联盟发布的《海量数据处理技术金融应用研究报告》。
加入“数治x”行业社群, 300+ 高质量前沿资料免费下载,不只做个资料党,更开启你的自主个性化学习旅程,在公众号“idtzed”上回复“入”直通:
资料、学习、成长问答助手;
图解、模板、问卷行业工具包;
个人、团队数据素养水准评估;
数治连线产研导师专场直播等。
与我们有更多合作,定制你的数字推广直击目标潜在客户,扫码添加老邪企业微信。
在此声明以上观点和内容,仅代表原作者和出处,与数治网DTZed 无关,如有出错或侵犯到相关合法权益,请通过电邮与我们联系:cs@dtzed.com。