
近年来,AI 工程化的研究热度持续提升,其目的是帮助组织在数智化转型过程中,更高效、大规模地利用 AI 创造业务价值。人工智能研发运营体系(MLOps) 作为 AI 工程化重要组成部分,其核心思想是解决 AI 生产过程中团队协作难、管理乱、交付周期长等问题,最终实现高质量、高效率、可持续的 AI 生产过程。
MLOps 的发展呈现出逐渐成熟的态势,近几年国内外 MLOps 落地应用正持续快速推进,特别是在 IT、银行、电信等行业取得明显效果。与此同时,MLOps 行业应用成熟度不足,使得组织在制度规范的建立、流程的打通、工具链的建设等诸多环节面临困难。
因此本指南旨在成为组织落地 MLOps 并赋能业务的“口袋书”,围绕机器学习全生命周期,为模型的持续构建、持续交付、持续运营等过程提供参考, 推进组织的 MLOps 落地进程,提高组织 AI 生产质效。
机器学习项目生命周期伴随着 AI 的发展早已形成,而 MLOps 的出现驱动产业界对机器学习项目生命周期进行了完整梳理。本章由信通院和行业专家结合机器学习和 MLOps 相关理论研究和产业实践, 围绕机器学习项目的全生命周期,对业界现有的 MLOps 框架体系做出总结归纳。
(一)机器学习项目生命周期
机器学习项目以需求、数据、代码、算法为输入,以模型、模型服务为输出,其生命周期主要包括定义问题、数据收集、数据处理、模型训练、模型评估、模型部署等过程。

图 6 机器学习项目生命周期示意图
MLOps 围绕持续集成、持续部署、持续监控和持续训练,构建和维护机器学习流水线,并通过流水线的衔接形成全生命周期闭环体系。基于 MLOps 框架的机器学习项目生命周期通常包括需求设计、开发、交付和运营四个阶段,细分为需求管理、数据工程、模型开发、模型交付、模型运营等过程。
需求管理:根据商业目标与业务需求,开展可行性分析,编制技术需求和技术方案。
数据工程:将源数据处理成可用数据,并存储至合适位置便于流转。
模型开发:在实验环境中,对模型进行训练、参数调优、评估与选择等过程,得到最优模型。
模型交付:将模型与配置、代码和脚本等进行封装,生成可交付物,并部署至目标环境。
模型运营:在生产环境中为上线的模型服务提供监控和运营维护能力。

图 7 基于 MLOps 框架的机器学习项目生命周期示意图
(二)MLOps 流程架构
典型的 MLOps 流程架构包含需求分析与开发、数据工程流水线、模型实验工程流水线、持续集成流水线、模型训练流水线、模型服务流水线、持续监控流水线七个部分。
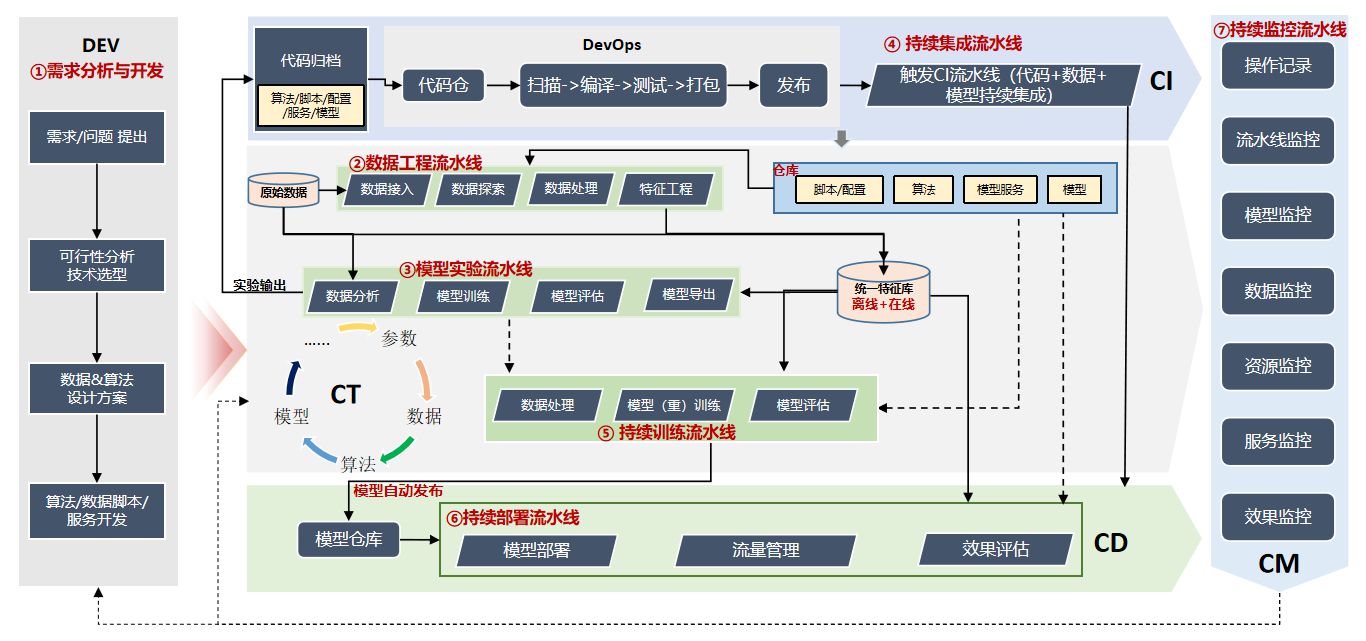
图 8 MLOps 流程架构示意图
1. 需求分析与开发
需求分析与开发是指对业务方的需求进行分析和设计,对规则、代码、脚本等进行开发。目的是解决机器学习项目中需求管理流程混乱、不同角色对于需求的理解不一致及风险不可控等问题,从源头提升项目质量,降低需求变更带来的影响。
主要输入:业务需求。
主要步骤:
1) 将业务需求转为技术问题,确定使用机器学习模型解决潜在业务问题的可行性及必要性,评估模型潜在的风险。
2) 设计机器学习项目架构,确定要使用的技术。
3) 梳理项目过程需要的数据,以及数据处理过程和规则(例如, 数据采集和标注规则,数据转换、清洗、特征选择和特征生成规则等),这些规则会根据后续的反馈持续迭代更新。
4) 开发对应的算法、训练代码、数据脚本、模型服务代码等。
5) 基于算法和脚本,触发数据工程和模型实验流程,得到最佳特征数据与模型参数等。
主要输出:项目计划,设计文档,用于数据工程、特征工程、模型训练及模型服务的代码与配置。
2. 数据工程流水线
数据工程流水线是指以流水线方式,对数据进行接入、处理、存储、分析等工程化处理。目的是解决数据来源繁杂、数据及特征难以共享、数据管理不统一等问题,为模型开发及模型服务提供干净可用的数据原料。
主要输入:原始数据、数据处理和特征工程的代码与配置。
主要步骤:
1) 接入并提取原始数据,包括流数据、静态批处理数据或云存储数据。
2) 对原始数据进行初步分析探索,挖掘并分析数据内部结构、分布等规律,检查数据质量。
3) 数据处理从数据清洗与转换开始,以预定义的转换规则作为输入,处理数据异常、缺失、冗余等问题,生成可用格式的数据作为输出。
4) 最大限度地从原始数据或处理后的数据中提取、变换为新的或更高级的特征,预定义的特征工程规则作为输入,将生成的特征作为输出,并存储至特征库。
主要输出:处理后的数据、特征。
3. 模型实验流水线
模型实验流水线是指以流水线方式,采用数据、算法和参数进行训练的实验过程。目的是解决过程难以回溯、实验难以复现、错误难以追查、参数难以配置和选择等问题,提高模型生产质量,并为持续训练提供基础。
主要输入:原始数据、特征、模型实验所需代码与配置。
主要步骤:
1) 利用特征库的能力,结合原始数据,开展数据分析,得到模型实验所需数据集。
2) 触发多轮模型训练,不断调整和选择性能最优算法和超参数。
3) 对不同模型参数进行交叉测试和验证,一旦性能指标达到预期, 迭代训练将会停止。模型训练和模型评估任务可根据条件重复触发。
4) 导出模型并提交至仓库,包括训练算法、数据脚本、服务代码、模型等。
主要输出:最佳算法、数据脚本、模型服务代码与配置、模型文件、实验指标。
4. 持续集成流水线
持续集成流水线是指以流水线方式,对模型和代码进行持续构建与集成的过程。目的是解决模型及代码构建、集成测试、安全扫描等过程繁琐、易出错、集成效率低下等问题,并以流水线的自动化提高交付质量。
主要输入:最佳算法、数据脚本、模型服务代码与配置、模型文件。
主要步骤:
1) 将代码、模型、配置等要素进行构建打包和集成测试,生产出可交付的部署包(例如镜像文件、JAR 包等)。
2) 将构建、测试、扫描等过程进行集成,以生成持续集成流水线。
3) 对集成过程出现的问题进行反馈和处理,提高集成成功率。
主要输出:部署包。
5. 持续部署流水线
持续部署流水线是指以流水线方式,将模型服务部署至目标环境并开展相应评估的过程。目的是解决部署周期长、部署配置易出错、部署进程启动晚、流量接入配置复杂、模型运行状态不稳定等问题, 做好模型为业务系统提供推理服务的充分准备。
主要输入:部署包、特征、服务工作流配置(例如更新策略或 AB 实验策略等)。
主要步骤:
1) 将模型服务部署至目标环境,并通过更新策略将新版本模型服务进行持续部署。
2) 对已部署模型服务配置相应流量管理策略,使其按照策略有序接入流量并开展验证和评估工作。
3) 根据已分配流量在模型上的运行结果,评估模型效果优劣,驱动模型优化。
主要输出:模型服务、评估报告。
6. 持续训练流水线
持续训练流水线是指以流水线方式,依据相关条件的触发持续对模型进行训练的过程。目的是解决数据漂移、模型服务不符合预期等业务问题,以及重新训练复杂耗时等效率问题,提高模型自生产能力。
主要输入:流水线配置(包括节点、触发条件、参数等)、旧数据、新数据、特征。
主要步骤:
1) 从特征库自动提取版本化特征。
2) 自动化开展数据准备和验证,并拆分数据集。
3) 根据模型实验阶段已选择的算法和超参数,对新数据进行自动训练。
4) 执行自动化的模型评估、超参数迭代。
5) 训练后的模型被导出并保存至模型仓库。
6) 根据需要触发模型测试及持续部署流水线。
主要输出:新模型。
7. 持续监控流水线
持续监控流水线是指以流水线方式,贯穿 MLOps 端到端生命周期,持续对过程和结果开展监控,同时在特定场景特定条件下触发模型重新训练的过程。目的是解决模型效果下降的问题,通过监控发现问题并持续改进,提高过程流转效率,确保模型服务质量。
主要输入:各类指标数据。
主要步骤:
1) 收集各类指标值,并进行记录和保存。
2) 根据既定规则开展数据分析。
3) 根据分析结果生成报告,必要时为触发器提供数据。
主要输出:分析结果、触发值。
(三)MLOps 相关角色
尽管机器学习模型的构建主要由数据科学家完成,但要最终为业务系统提供推理服务却需要多角色合作。组织应围绕 MLOps 流程的持续运转,明确角色与分工,可提高多角色间的协作效率,从而提升整体生产效率和质量。下图展示了 MLOps 相关角色分工示意图,但由于 MLOps 领域的飞速发展,将来可能出现的新角色暂未列出。同时,在许多组织中,各角色可能是专职或兼任,具体如何安排应视组织结构和业务场景等情况而定。
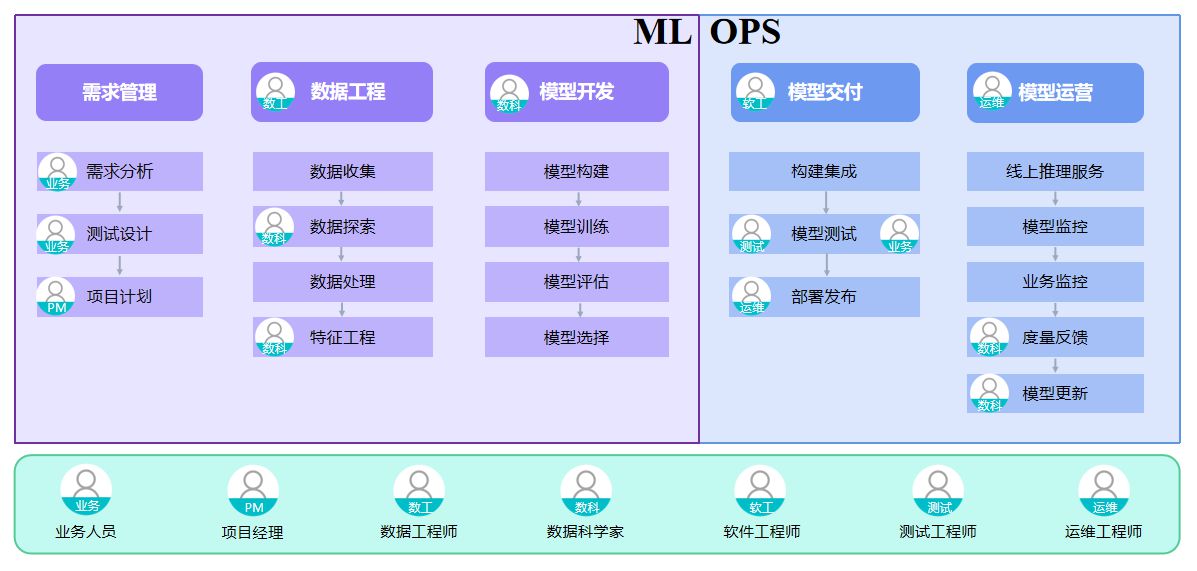
图 9 MLOps 相关角色分工示意图
典型 MLOps 相关角色分工包含业务人员、项目经理、机器学习架构师、数据工程师、数据科学家、软件工程师、测试工程师和运维工程师等。表 1 展示了在实际的机器学习项目全生命周期中,业务人员、数据科学家等各类角色所关注的不同重点及具体的工作职责。
表 1 MLOps 相关角色职责要求,详见全文
值得关注的是,近年来行业开始出现 MLOps 工程师角色,职责主要包括 MLOps 平台部署与维护、流水线构建与管理、模型优化、度量改进等。MLOps 工程师在Linkedln 新兴职业排行榜中高居榜首, 五年内增长了 9.8 倍10。国内绝大部分组织中的 MLOps 工程师职责由数据科学家、软件工程师或运维工程师兼任,相信随着 MLOps 的普及与发展,MLOps 工程师将成为专职岗位。
实践案例:中原银行的模型风险分析师
中原银行在风险合规要求较高的场景中,设置模型风险分析师的角色,对数据科学家开发的模型进行验证评估,确保模型设计方案、开发过程满足既定的业务诉求,并满足监管、合规等相关政策要求。
- 模型需求设计,结合统计方法与专家经验,验证模型原理和方法的合理性、模型的可用场景和局限性,清晰理解模型的特征、影响及参数估计情况,确保满足业务需求。
- 建模过程验证,检查建模过程的合理性,包括需求管理、数据工程、模型开发等过程的准确性、合规性、可控性。
- 模型效果验证,将模型输出结果与真实结果进行比较,检验概率、模型参数的区分能力、准确性、稳定性等,确保模型稳定可靠。
本文摘编自中国信通院云计算与大数据研究所、人工智能关键技术和应用评测工业和信息化部重点实验室联合发布的《人工智能研发运营体系(MLOps)实践指南(2023年)》,全文下载:
人工智能研发运营体系(MLOps)实践指南(2023年)
更多标准、白皮书、报告等高质量纯净资料下载,在文末扫码关注官方微信公众号“idtzed”,进入公众号菜单“治库”,或按自动回复发送引号内关键词。


