
如果说 2022 年被称为生成式人工智能之年,扩散模型应用取得突破,ChatGPT 出世,一系列开创性的研究论文发表, 2023 年则把大模型推向了一个高峰,GPT-4 的发布,标志着生成式人工智能,进入了面朝通用人工智能创新应用的阶段。应用、研究、监管,合力开辟着生成式人工智能的发展之路。
生成式人工智能的生态包括了基础设施层、模型层与应用层,创新在每一个层面发起,竞争也在科技巨头、行业龙头和初创公司之间展开。面对这一革命性的技术,不论是主动还是被动,企业都被卷入其中。不管是技术的守成者、创新者还是采纳者,业务模式都将发生变化,进而影响企业的发展。
在整个生态中,受益于以参数规模为代表的大模型不断扩张,算力目前是最稀缺的资源,也处于最容易获利的要津。算力是大模型成本结构中最大的一块,GPU 的性能,决定了这个新兴行业的步调。但是,GPU 性能提升的速度,已经落后于大模型训练和推理需求的增长。
当前,生成式 AI 尚处于技术发展的早期阶段,基础架构和核心技术并不成熟;科技巨头忙于研发大模型,尚未顾及深度切入具体的应用场景。但巨头何时添加相似的功能(feature)始终是悬在初创企业头上的达摩克利斯之剑,而大模型能力边界的扩张也可能在未来挤占初创企业的发展空间,可以说,这是初创企业的蓝海,但也有发展道路上的暗礁。
在中国,目前从模型出发的公司受到看好,通用大模型和垂直大模型的创业如火如荼,而自建模型的应用也在努力构建着自己的壁垒,同样,科技巨头正在利用自身算力优势来构建大模型。我们有理由相信,在众多模型层和科技大厂的合力下,模型层的整体能力将进一步完善,在未来为应用层企业提供可靠的支撑。
GPT-3 之后的新公司
与 2022 年受到 Stable Diffusion 和 ChatGPT 刺激后快速涌现出的生产力工具方向的创业公司不同,2023 年有更多比例的新公司聚焦在底层技术的创新上,更多大模型公司和 infra 工具链公司在以技术大拿为主的创始人主导下成立。此外,在生产力工具的方向上,不同于此前仅微调Stable Diffusion 等开源模型的创业公司,最新涌现的创业公司往往由更高级别的AI 人才领导。
大模型创业公司开始分化,在通用大模型创业公司方兴未艾的同时,许多面向特定行业的垂直大模型公司开始出现,主要聚焦在医疗、电商、科研、工业、自动驾驶和机器人等方向。
.jpg)
具备行业属性的智能助手方向的创业企业开始增加,如求职、招聘、求学、法律、健康、购物、企业知识问答等方向的个人助手和员工助手方向的创业公司持续涌现,这代表着在经过一段时间对 ChatGPT、Stable Diffusion 的熟悉后,具备更强行业知识和资源的行业老炮型创始人逐渐进入生成式 AI 领域。
大模型公司
通用大模型
作为模型层公司代表的 OpenAI,2020 年发布的 1750 亿参数的 GPT-3 曾一度是 AI 历史上最大的机器学习模型,相比于 15 亿参数量的 GPT-2,GPT-3 参数量提高约 117 倍, 预训练的数据量也从 50 GB 提高到 570 GB。2023 年 3 月, OpenAI 发布的 GPT-4 则再次扩展了深度学习的边界,结合多模态能力达到了里程碑式的效果,并在各种专业和学术基准上表现出可以与人类媲美的水平。 可以说,GPT-3 打响了大模型竞争的第一枪,而 ChatGPT 和 GPT-4 的出现进一步加速了大模型主导权的竞争,是否拥有一个大语言模型底座对于大模型企业后续进一步优化出更好的模型至关重要。 ChatGPT 是 OpenAI GPT-3.5 优化后的模型和产品化体现,其背后的技术从 2018 年的 GPT-1(2018)开始,逐渐经过 GPT-2(2019),GPT-3(2020)逐渐达到里程碑式的突破,此后 2 年内 GPT-3 又经过两次重要迭代,引入基于人类的反馈系统(RLHF)后形成 ChatGPT。从 ChatGPT 的发展可以看出,对于模型层公司来说,技术的演进极为重要,公司需要极强的技术掌舵人和融资能力来保障研发投入的稳定性。
此外,通过对海外市场的观察,我们发现当前大模型竞赛中,由高级别 AI 人才主导的创业公司更加领先,例如 OpenAI, Anthropic 和Cohere 等公司。同样,类似Adept, Inflection 和 Character.ai 等公司以极快速度实现了极高的估值,也表明顶级的 AI 人才正在通过研发大模型来构建有壁垒的应用,以此参与到生成式 AI 领域的竞赛中,而市场也更青睐这些顶级 AI 人才创立的公司。
同样,目前中国市场普遍看好从模型出发的公司,当前大模型公司具备以下三个特点:
- 投入大:底层模型的构建需要超重资源投入,包括大量算力、数据和人才;
- 工程强:由于大模型具备更强的泛化能力和提供方的商业追求,大模型发布时就提供各类用法的样例;
- 营销强:受到 OpenAI 高调营销(如高管频繁接受各种访谈)的带动,国内大模型公司召开发布会已经成为常态。
在通用大模型百舸争流的今天,国内绝大多数的大模型团队在 2023 年之后成立,在同时起步并角逐大模型皇冠的路上,团队至关重要。正如 GPT-4 报告中披露的,研发出 GPT- 4 至少需要六个方向的研究团队一样(Pretraining, Long context, Vision, Reinforcement Learning & Alignment, Evaluation & Analysis, and Deployment),国内大模型创业团队需要有极强的算法、工程和数据能力:
- 将市面上存在的算法用艺术的形式组合起来,成为最终模型的某个环节;
- GPT-4 未公开算法,企业需要创造性地提出自研算法才能研发出达到或超过 GPT-4 效果的通用大模型;
- 基础模型的研发需要极强的分布式训练等工程能力的支持,团队需要确保对计算资源的高效利用,并建设高质量数据集以保证模型的效果。
当然,巨头不会懈怠,如何与科技巨头竞争和合作,始终是贯穿初创企业成长始终的难题。国内科技巨头几乎每周都会宣布大模型的研发进展与行业合作动态,它们横跨了云基础设施与大模型,而且在它们那里模型层与应用层的界限相对模糊。百度宣称要把所有的产品都重做一遍,而坐拥最多用户的腾讯决定先聚焦产业。但竞争的关键,还是提供效果最优的模型,辅之以足够可靠的产品与服务。
垂直大模型
垂直大模型企业往往不会作为模型提供商来存在,更多的是 “自建大模型的垂直应用”的模式。 除了创业公司以外,有兴趣研发垂直大模型的组织主要还有互联网公司、AI 1.0 企业和行业龙头等。
对于自研垂直模型的企业,行业数据尤为重要,拥有高质量的行业数据和私有数据,是针对特定行业优化大模型表现的关键。以彭博自研的 BloomBergGPT 为代表,金融行业数据超过了公开数据,占比达到 51%。因此,最终模型效果在很多在金融任务上有出色的表现。
目前构建面向垂直行业的模型有以下三种方式:
- 在已经完成训练的通用大模型基础上,结合大量自身的行业数据进行微调(fine-tuning),在此之前是否对通用大模型进行蒸馏、后续是否外挂知识库则视情况而定。
- 通过改变数据的分布,结合更多特定行业的数据进行预训练,直接打造行业大模型
- 通过自定义一种专属语言,并用(文本,专属语言)这样的 pair 对大模型进行 fine-tuning,并将生成的专属语言输入到自研的 AI 模型中,完成【用户输入 – 大模型 – 专属语言输出 – 自有 AI 模型 – 业务结果输出】的全过程。
应用层公司
模型层公司的分量虽重,应用层公司的数量仍是最多的。这是创新最活跃的地方。绝大多数应用层公司的创业者不需要从头训练大模型,只需要直接利用底座模型的能力,叠加对于场景和行业的深刻理解,就可以支持一家应用公司的发展。
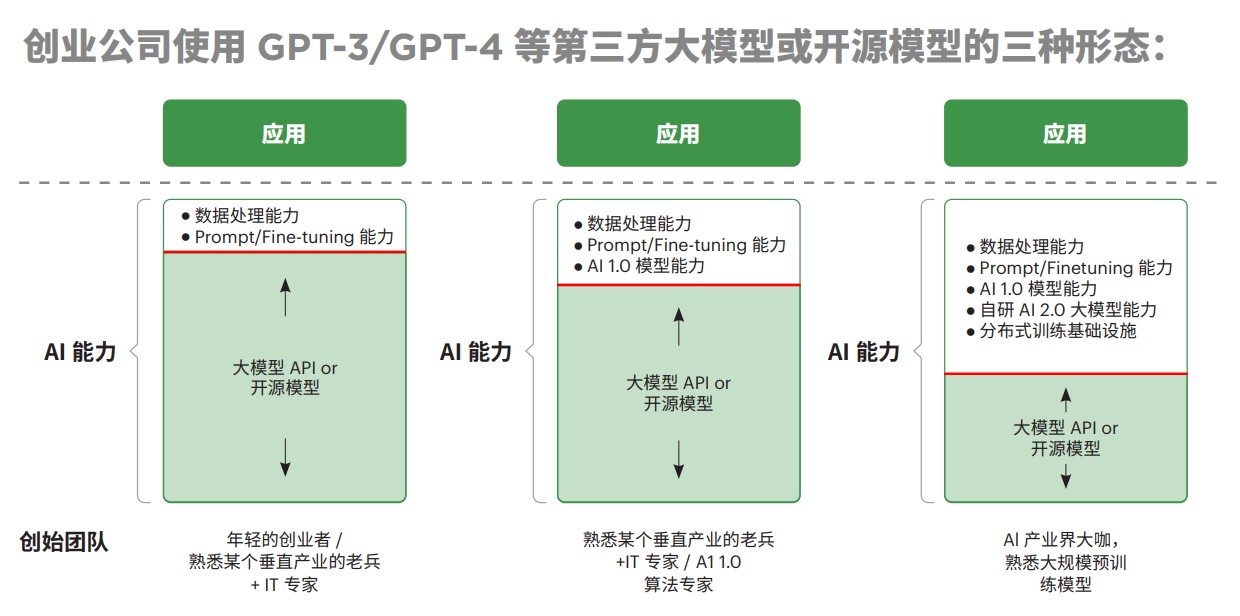
根据AI 能力来源及其占比,这些应用公司大致可以分为三类:
- 调用外部大模型的 API 为主的模式。这类团队本身通常不会有很强的预训练模型开发能力,更多是具备应用层的能力。他们往往是年轻创业者,或是来自垂直产业的老兵,搭配几位 IT 专家,基于 API 或开源模型去开发应用,至多做一些微调与修改。
- 结合了 AI 1.0 模型能力的模式。他们仍以调用 API 或使用开源模型为主,但又涉及大模型技术以外的 AI 算法。这类团队内部培养了一些深度学习算法的工程师,才能更好地实现既定效果。
- 自研 AI 2.0 模型能力的模式。这就是“模型 + 应用”的垂直大模型模式。这类团队通常需要高度熟练的机器学习科学家、大量相关的数据、训练基础设施和计算能力。团队领袖往往是 AI 行业的顶尖人才,有过成功的大模型预训练经验。当然,这些公司也不会介意借鉴一些开源模型加快研发速度。
三类模式并没有孰优孰劣之分。不同应用场景,不同发展阶段,需要合理采用不同的模式。随着调用API 为主的初创企业逐步发展,团队变得更为成熟,会很自然地将提升自身 AI能力提上日程。
如果没有自研AI 2.0 模型的能力,想要成功,就要快速推出产品并占领市场,并持续领先的迭代出更合适客户的产品。它的产品或服务,成为工作流程中的一环,或建立新的用户社区,是能否持续快速规模化的关键。但长期来看,它的竞争壁垒仍是传统软件的规模效应、切换成本,而技术壁垒较低,最底层技术很难实现差异化。
调用外部大模型的 API 为主的模式,它们还面临被原厂大模型迭代到下一个版本后吃掉市场的威胁。而结合了 AI 1.0 模型能力的模式,也将面临大量同质化产品的竞争,即便公司在早期发现了蓝海市场,在实现产品与市场的匹配(PMF)后,也可能引起竞争对手快速跟进,并且容易受到科技大厂的竞争。
自研 AI 2.0 模型,想要成功,就要持续拿到大量融资,在实现对早期大众的占领前,始终保持自研模型效果不低于第三方模型,同时需要兼顾好产品打磨、业务发展、销售和营销等。它们面临较少的同行业竞争对手,但面临大模型边界扩展的威胁。它的竞争壁垒在于,如何扩大自己的技术领先优势与资本投资热情。
语言类应用公司
在全球范围内,基于自然语言处理的应用,在 transformer 应用中的占比 40%。在国内,根据启明创投交流过的公司统计,语言类应用占了近三年成立的生成式 AI 企业的 27%,此外,多模态类应用中还有占比近 1/3 离不开自然语言处理。
语言类公司,按功能来分,可以分为翻译、对话、摘要、生成、推理等,可以用于构筑智能对话、智能助手、智能服务与生产力工具;按应用场景来分,这些公司出现在社交、咨询、招聘、健康、心理、金融、法律与营销等领域。
语言类公司面临强大的竞争对手。微软的生产力套件挤压了原生应用的市场空间;排名靠前的全球 SaaS 巨头纷纷推出自己的语言类 AI 应用,部分还是自研的大模型。
不同应用场景决定了语言类公司不同的竞争策略,有些场景需要快速跑出流量占得先机,比如招聘和社交,流量爆发后形成的规模效应将是这些场景下创业公司的核心壁垒;而另外一些场景,则需要深耕行业,例如金融、法律、心理和营销,具备信心的创始人还需要有极强的行业认知,在攻下一个个行业客户 / 用户后,切换成本将为他们建立显著的优势。
简单的文本处理和套壳的 Chatbot,将很快成为红海。创业公司要从取悦早期用户的兴奋中冷静下来,构筑更高的壁垒。自然语言正在成为一种新的交互界面,连接用户与世界。问题不断出现,知识不断更新,绝大多数用户并不仅仅满足获取可能与事实不符的娱乐性对话,如何把知识嵌入到大模型的需求非常迫切,当前相关技术和产品尚供给不足,仍处于蓝海状态。
文本模态的应用企业,要警惕被自己杀死。它需要对齐来满足公众价值和国家的监管要求。越来越多的生成式人工智能,正在制造良莠不齐的文本内容,它们会成为训练数据,也会成为搜索来源。谁先解决这个问题,谁拥有更广阔的的发展空间。同样,如何帮助 Facebook 和 Twitter 这样的社交网络或用户社区防止泛滥的 AI 数字人和 AI 回复,也将带来不小的创业机会。
多模态应用公司
多模态方向上的技术创新与应用场景,也为中国的生成式 AI 应用公司提供了巨大机会。在中国庞大的互联网、消费市场、实体经济中,蕴藏着丰富的多模态数据。同样,抖音、快手、微视等短视频或直播应用也占据了用户大量的时间。
最早的一批多模态应用经过将近一年的发展,已经有公司的总注册用户量突破百万甚至两百万,并初步实现了早期的商业化收入。但如何进一步扩大用户量,或深入到游戏、电商等特定行业实现大规模收入的路径尚不清晰。另外,更强技术背景的创始人正在进入这个赛道,准备研发更强劲的模型来解决可控性等问题。未来,如何从创意工具走向可控性极强的生产力工具,将是多模态应用公司需要回答的关键问题。
与 Text-to-Image 企业已经拥有了相对不错的生成效果,而在争夺可控性的制高点不同,Text-to-Video 和 Text-to-3D 企业则在比拼生成内容的效果。视频和 3D 生成领域尚未出现如图像领域的 Stable Diffusion 一样风靡一时的模型,因此,这些方向上的公司进入商业化阶段的条件并不充分,需要通过模型层面的创新(无论是自研还是使用第三方模型),来生成符合用户预期的内容。
数字人企业重新焕发生机,在 AI2.0 到来之前,它们拥有很强的 CG(计算机图形学)能力,但对话能力却显得薄弱,很多情况下是没有灵魂的皮囊。大模型的出现补足了数字人企业的短板,让通用的 to C 数字人可以和用户进行更丰富和深入的交互,基于内容提供更强的情感链接;并让to B 数字人从原来的“客户宣传需求驱动”和“电商平台合规驱动”,真正走向“效果驱动”。然而,大模型也激化了数字人企业的竞争,原本独特的 NLP 能力如今不再新鲜,通过接入大模型 API,每个应用公司都轻易具备。
当前,多模态的应用正在超越虚拟世界,向具身智能领域进军,从而直接与现实世界进行互动。例如,机器人需要在虚拟环境中模拟和仿真各种操作、理解用户的需求、感知周围物理世界的环境并规划要实现的动作。
总之,当前多模态方向上的创业公司尚处于发展的早期阶段,商业的想象力让这条赛道充满前景,但技术的不成熟又让这个方向充满了挑战。这个方向的创业公司同样面临着生成式 AI 公司无法回避的问题――即用户被生成的内容所吸引,与传统的 CRM 和 ERP 等软件不同,生成式 AI 的用户并没有表现出足够的粘性和切换成本。用户跟着优质的内容走,而谁能够提供优质的内容,就可以在提高渗透率的同时,把竞争对手的用户吸引过来。在技术尚未成熟的今天,谁能够提供更优质的模型,往往意味着能够提供更优质的内容,吸引更多的用户。可以说,致力于在多模态方向上打造出爆款应用的创业公司,必须具备极强的模型研发能力和创新能力。简单来说,颠覆式的 AI 应用的核心驱动力来自于底层模型的创新,两者无法解耦,一定时间内,模型的作用将大于产品设计的作用。
本文摘编自启明创投、未尽研究发布的《生成式 AI 报告》,全文下载:
更多标准、白皮书、报告等高质量纯净资料下载,在文末扫码关注官方微信公众号“idtzed”,进入公众号菜单“治库”,或按自动回复发送引号内关键词。

-228x171.jpg)
